Beyond Naive RAG: Build Smarter Systems with Query Routing and Hybrid Retrieval
Your RAG pipeline retrieves documents for every query, regardless of whether retrieval is needed. It runs the same similarity search on code, natural language, and financial reports. And when results are bad, you have no way to tell which stage broke.
These are symptoms of naive RAG—a fixed pipeline that treats every query the same way. Modern RAG systems work differently. They route queries to the right handler, combine multiple retrieval methods, and evaluate each stage independently.
This article walks through a four-node architecture for building smarter RAG systems, explains how to implement hybrid retrieval without maintaining separate indexes, and shows how to evaluate each pipeline stage so you can debug problems faster.
Why Long Context Doesn’t Replace RAG
“Just put everything in the prompt” is a common suggestion now that models support 128K+ token windows. It doesn’t hold up in production for two reasons.
Cost scales with your knowledge base, not your query. Every request sends the full knowledge base through the model. For a 100K-token corpus, that’s 100K input tokens per request—regardless of whether the answer requires one paragraph or ten. Monthly inference costs grow linearly with corpus size.
Attention degrades with context length. Models struggle to focus on relevant information buried in long contexts. Research on the “lost in the middle” effect (Liu et al., 2023) shows that models are more likely to miss information placed in the middle of long inputs. Larger context windows haven’t solved this—attention quality hasn’t kept pace with window size.
RAG avoids both problems by retrieving only the relevant passages before generation. The question isn’t whether RAG is needed—it’s how to build RAG that actually works.
What’s Wrong with Traditional RAG?
Traditional RAG follows a fixed pipeline: embed the query, run vector similarity search, take the top-K results, generate an answer. Every query follows the same path.
This creates two problems:
Wasted compute on trivial queries. “What is 2 + 2?” doesn’t need retrieval, but the system runs it anyway—adding latency and cost for no benefit.
Brittle retrieval on complex queries. Ambiguous phrasing, synonyms, or mixed-language queries often defeat pure vector similarity. When retrieval misses relevant documents, generation quality drops with no fallback.
The fix: add decision-making before retrieval. A modern RAG system decides whether to retrieve, what to search for, and how to search—rather than blindly running the same pipeline every time.
How Modern RAG Systems Work: A Four-Node Architecture
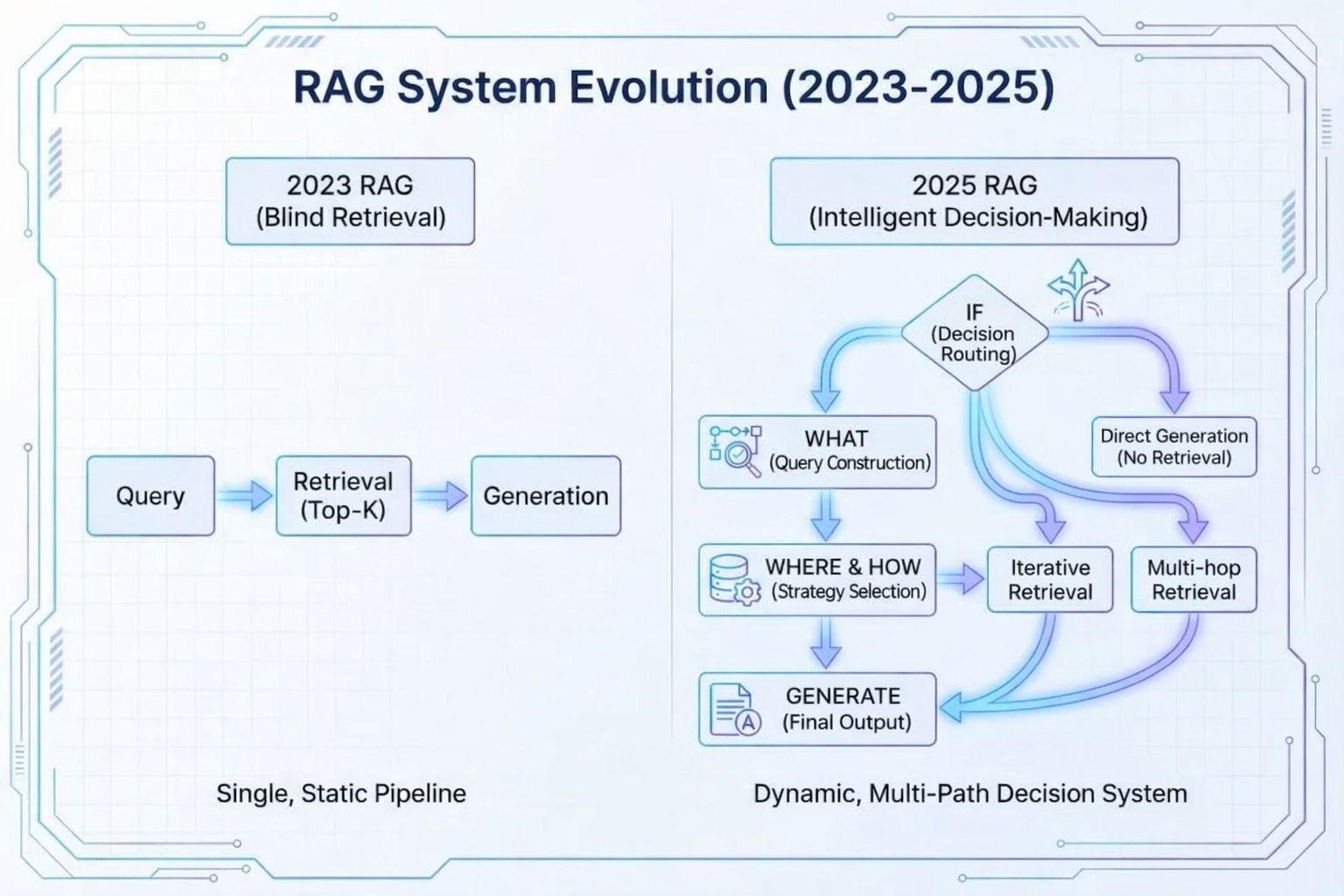
Instead of a fixed pipeline, a modern RAG system routes each query through four decision nodes. Each node answers one question about how to handle the current query.
Node 1: Query Routing — Does This Query Need Retrieval?
Query routing is the first decision in the pipeline. It classifies the incoming query and sends it down the appropriate path:
| Query Type | Example | Action |
|---|---|---|
| Common-sense / general knowledge | “What is 2 + 2?” | Answer directly with the LLM—skip retrieval |
| Knowledge-base question | “What are the specs for Model X?” | Route to the retrieval pipeline |
| Real-time information | “Weather in Paris this weekend” | Call an external API |
Routing upfront avoids unnecessary retrieval for queries that don’t need it. In systems where a large share of queries are simple or general-knowledge, this alone can cut compute costs significantly.
Node 2: Query Rewriting — What Should the System Search For?
User queries are often vague. A question like “the main numbers in LightOn’s Q3 report” doesn’t translate well into a search query.
Query rewriting transforms the original question into structured search conditions:
- Time range: July 1 – September 30, 2025 (Q3)
- Document type: Financial report
- Entity: LightOn, Finance department
This step bridges the gap between how users ask questions and how retrieval systems index documents. Better queries mean fewer irrelevant results.
Node 3: Retrieval Strategy Selection — How Should the System Search?
Different content types need different retrieval strategies. A single method can’t cover everything:
| Content Type | Best Retrieval Method | Why |
|---|---|---|
| Code (variable names, function signatures) | Lexical search (BM25) | Exact keyword matching works well on structured tokens |
| Natural language (docs, articles) | Semantic search (dense vectors) | Handles synonyms, paraphrases, and intent |
| Multimodal (charts, diagrams, drawings) | Multimodal retrieval | Captures visual structure that text extraction misses |
Documents are tagged with metadata at indexing time. At query time, these tags guide both which documents to search and which retrieval method to use.
Node 4: Minimal-Context Generation — How Much Context Does the Model Need?
After retrieval and reranking, the system sends only the most relevant passages to the model—not entire documents.
This matters more than it sounds. Compared with full-document loading, passing only the relevant passages can reduce token usage by over 90%. Lower token counts mean faster responses and lower costs, even when caching is in play.
Why Hybrid Retrieval Matters for Enterprise RAG
In practice, retrieval strategy selection (Node 3) is where most teams get stuck. No single retrieval method covers all enterprise document types.
Some argue that keyword search is sufficient—after all, Claude Code’s grep-based code search works well. But code is highly structured, with consistent naming conventions. Enterprise documents are a different story.
Enterprise Documents Are Messy
Synonyms and varied phrasing. “Optimize memory usage” and “reduce memory footprint” mean the same thing but use different words. Keyword search matches one and misses the other. In multilingual environments—Chinese with word segmentation, Japanese with mixed scripts, German with compound words—the problem multiplies.
Visual structure matters. Engineering drawings depend on layout. Financial reports rely on tables. Medical images depend on spatial relationships. OCR extracts text but loses structure. Text-only retrieval can’t handle these documents reliably.
How to Implement Hybrid Retrieval
Hybrid retrieval combines multiple search methods—typically BM25 for keyword matching and dense vectors for semantic search—to cover what neither method handles alone.
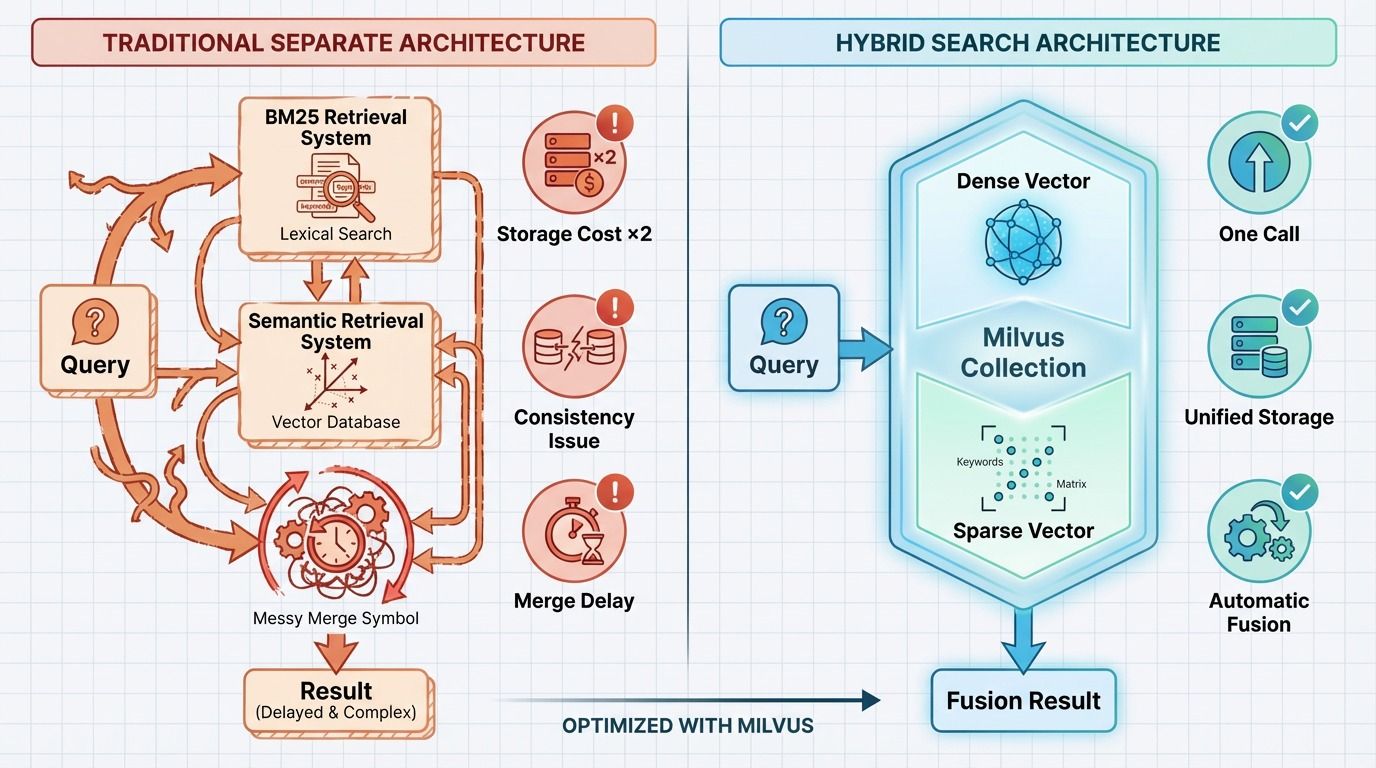
The traditional approach runs two separate systems: one for BM25, one for vector search. Each query hits both, and results are merged afterward. It works, but it comes with real overhead:
| Traditional (Separate Systems) | Unified (Single Collection) | |
|---|---|---|
| Storage | Two separate indexes | One collection, both vector types |
| Data sync | Must keep two systems in sync | Single write path |
| Query path | Two queries + result merging | One API call, automatic fusion |
| Tuning | Adjust merge weights across systems | Change dense/sparse weight in one query |
| Operational complexity | High | Low |
Milvus 2.6 supports both dense vectors (for semantic search) and sparse vectors (for BM25-style keyword search) in the same collection. A single API call returns fused results, with retrieval behavior adjustable by changing the weight between vector types. No separate indexes, no sync issues, no merge latency.
How to Evaluate a RAG Pipeline Stage by Stage
Checking only the final answer isn’t enough. RAG is a multi-stage pipeline, and a failure at any stage propagates downstream. If you only measure answer quality, you can’t tell whether the problem is in routing, rewriting, retrieval, reranking, or generation.
When users report “inaccurate results,” the root cause could be anywhere: routing may skip retrieval when it shouldn’t; query rewriting may drop key entities; retrieval may miss relevant documents; reranking may bury good results; or the model may ignore the retrieved context entirely.
Evaluate each stage with its own metrics:
| Stage | Metric | What It Catches |
|---|---|---|
| Routing | F1 score | High false-negative rate = queries needing retrieval are skipped |
| Query rewriting | Entity extraction accuracy, synonym coverage | Rewritten query drops important terms or changes intent |
| Retrieval | Recall@K, NDCG@10 | Relevant documents aren’t retrieved, or are ranked too low |
| Reranking | Precision@3 | Top results aren’t actually relevant |
| Generation | Faithfulness, answer completeness | Model ignores retrieved context or gives partial answers |
Set up layered monitoring. Use offline test sets to define baseline metric ranges for each stage. In production, trigger alerts when any stage drops below its baseline. This lets you catch regressions early and trace them to a specific stage—instead of guessing.
What to Build First
Three priorities stand out from real-world RAG deployments:
Add routing early. Many queries don’t need retrieval at all. Filtering them upfront reduces load and improves response time with minimal engineering effort.
Use unified hybrid retrieval. Maintaining separate BM25 and vector search systems doubles storage costs, creates sync complexity, and adds merge latency. A unified system like Milvus 2.6—where dense and sparse vectors live in the same collection—eliminates these issues.
Evaluate each stage independently. End-to-end answer quality alone is not a useful signal. Per-stage metrics (F1 for routing, Recall@K and NDCG for retrieval) let you debug faster and avoid breaking one stage while tuning another.
The real value of a modern RAG system isn’t just retrieval—it’s knowing when to retrieve and how to retrieve. Start with routing and unified hybrid search, and you’ll have a foundation that scales.
If you’re building or upgrading a RAG system and running into retrieval quality issues, we’d love to help:
- Join the Milvus Slack community to ask questions, share your architecture, and learn from other developers working on similar problems.
- Book a free 20-minute Milvus Office Hours session to walk through your use case—whether it’s routing design, hybrid retrieval setup, or multi-stage evaluation.
- If you’d rather skip the infrastructure setup, Zilliz Cloud (managed Milvus) offers a free tier to get started.
A few questions that come up often when teams start building smarter RAG systems:
Q: Is RAG still necessary now that models support 128K+ context windows?
Yes. Long context windows help when you need to process a single large document, but they don’t replace retrieval for knowledge-base queries. Sending your entire corpus with every request drives up costs linearly, and models lose focus on relevant information in long contexts—a well-documented issue known as the “lost in the middle” effect (Liu et al., 2023). RAG retrieves only what’s relevant, keeping costs and latency predictable.
Q: How do I combine BM25 and vector search without running two separate systems?
Use a vector database that supports both dense and sparse vectors in the same collection. Milvus 2.6 stores both vector types per document and returns fused results from a single query. You adjust the balance between keyword and semantic matching by changing a weight parameter—no separate indexes, no result merging, no sync headaches.
Q: What’s the first thing I should add to improve my existing RAG pipeline?
Query routing. It’s the highest-impact, lowest-effort improvement. Most production systems see a significant share of queries that don’t need retrieval at all—common-sense questions, simple calculations, general knowledge. Routing these directly to the LLM cuts unnecessary retrieval calls and improves response time immediately.
Q: How do I figure out which stage of my RAG pipeline is causing bad results?
Evaluate each stage independently. Use F1 score for routing accuracy, Recall@K and NDCG@10 for retrieval quality, Precision@3 for reranking, and faithfulness metrics for generation. Set baselines from offline test data and monitor each stage in production. When answer quality drops, you can trace it to the specific stage that regressed instead of guessing.
- Why Long Context Doesn't Replace RAG
- What's Wrong with Traditional RAG?
- How Modern RAG Systems Work: A Four-Node Architecture
- Node 1: Query Routing — Does This Query Need Retrieval?
- Node 2: Query Rewriting — What Should the System Search For?
- Node 3: Retrieval Strategy Selection — How Should the System Search?
- Node 4: Minimal-Context Generation — How Much Context Does the Model Need?
- Why Hybrid Retrieval Matters for Enterprise RAG
- Enterprise Documents Are Messy
- How to Implement Hybrid Retrieval
- How to Evaluate a RAG Pipeline Stage by Stage
- What to Build First
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



