Drag, Drop, and Deploy: How to Build RAG Workflows with Langflow and Milvus
Building an AI workflow often feels harder than it should. Between writing glue code, debugging API calls, and managing data pipelines, the process can eat up hours before you even see results. Langflow and Milvus simplify this dramatically — giving you a code-light way to design, test, and deploy retrieval-augmented generation (RAG) workflows in minutes, not days.
Langflow offers a clean, drag-and-drop interface that feels more like sketching ideas on a whiteboard than coding. You can visually connect language models, data sources, and external tools to define your workflow logic — all without touching a line of boilerplate code.
Paired with Milvus, the open-source vector database that gives LLMs long-term memory and contextual understanding, the two form a complete environment for production-grade RAG. Milvus efficiently stores and retrieves embeddings from your enterprise or domain-specific data, allowing LLMs to generate answers that are grounded, accurate, and context-aware.
In this guide, we’ll walk through how to combine Langflow and Milvus to build an advanced RAG workflow — all through a few drags, drops, and clicks.
What is Langflow?
Before going through the RAG demo, let’s learn what Langflow is and what it can do.
Langflow is an open-source, Python-based framework that makes it easier to build and experiment with AI applications. It supports key AI capabilities such as agents and the Model Context Protocol (MCP), giving developers and non-developers alike a flexible foundation for creating intelligent systems.
At its core, Langflow provides a visual editor. You can drag, drop, and connect different resources to design complete applications that combine models, tools, and data sources. When you export a workflow, Langflow automatically generates a file named FLOW_NAME.json on your local machine. This file records all the nodes, edges, and metadata that describe your flow, allowing you to version-control, share, and reproduce projects easily across teams.
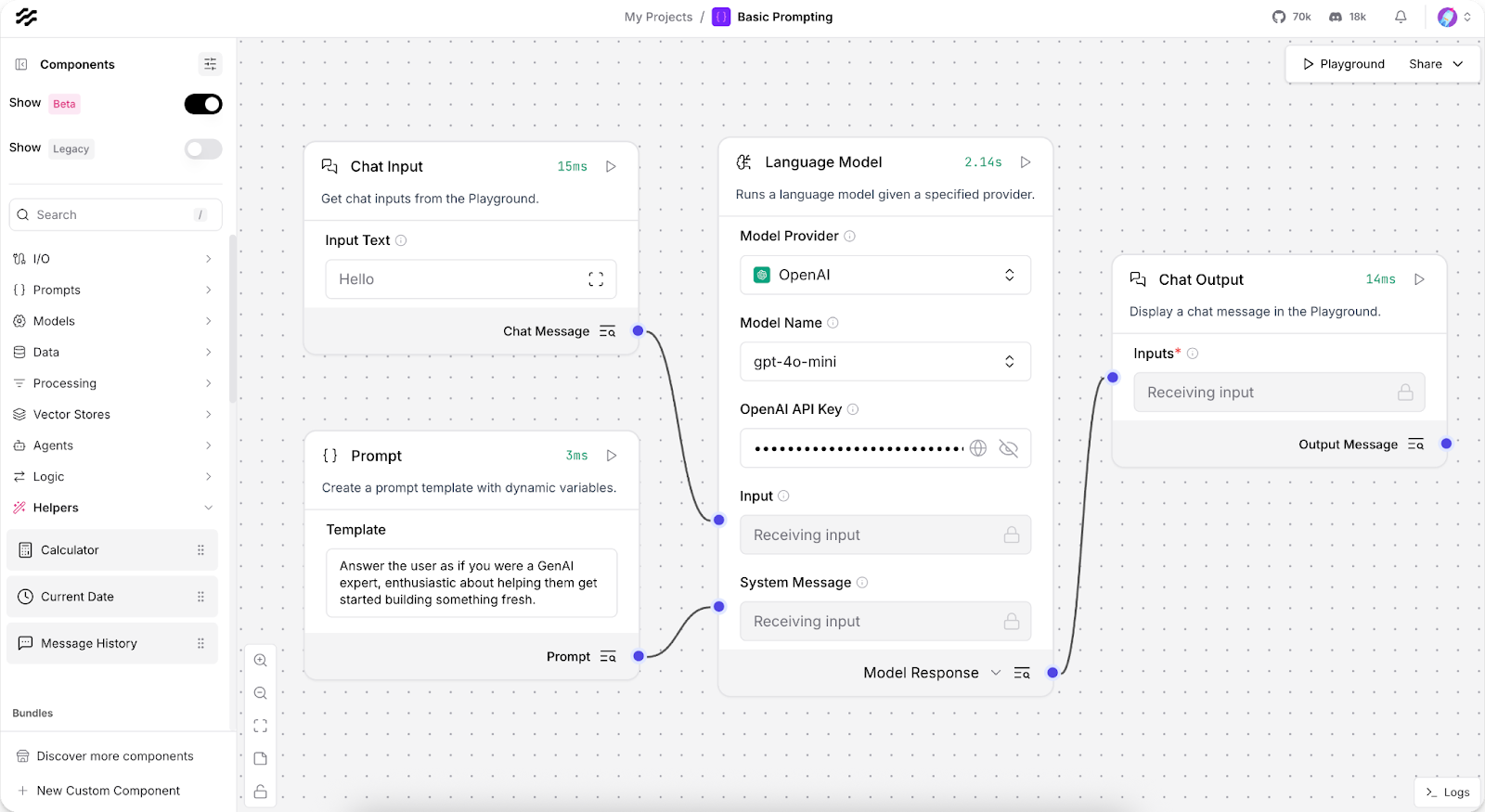
Behind the scenes, a Python-based runtime engine executes the flow. It orchestrates LLMs, tools, retrieval modules, and routing logic — managing data flow, state, and error handling to ensure smooth execution from start to finish.
Langflow also includes a rich component library with prebuilt adapters for popular LLMs and vector databases — including Milvus. You can extend this further by creating custom Python components for specialized use cases. For testing and optimization, Langflow offers step-by-step execution, a Playground for rapid testing, and integrations with LangSmith and Langfuse for monitoring, debugging, and replaying workflows end-to-end.
Hands-on Demo: How to Build a RAG Workflow with Langflow and Milvus
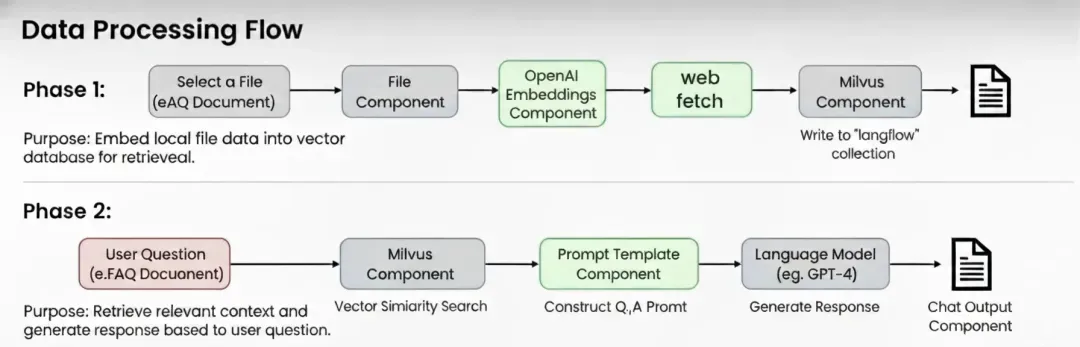
Building on Langflow’s architecture, Milvus can serve as the vector database that manages embeddings and retrieves private enterprise data or domain-specific knowledge.
In this demo, we’ll use Langflow’s Vector Store RAG template to demonstrate how to integrate Milvus and build a vector index from local data, enabling efficient, context-enhanced question answering.
Prerequisites:
1.Python 3.11 (or Conda)
2.uv
3.Docker & Docker Compose
4.OpenAI key
Step 1. Deploy Milvus Vector Database
Download the deployment files.
wget <https://github.com/Milvus-io/Milvus/releases/download/v2.5.12/Milvus-standalone-docker-compose.yml> -O docker-compose.yml
Start the Milvus service.
docker-compose up -d
docker-compose ps -a

Step 2. Create a Python Virtual Environment
conda create -n langflow
# activate langflow and launch it
conda activate langflow
Step 3. Install the Latest Packages
pip install langflow -U
Step 4. Launch Langflow
uv run langflow run
Visit Langflow.
<http://127.0.0.1:7860>
Step 5. Configure the RAG Template
Select the Vector Store RAG template in Langflow.
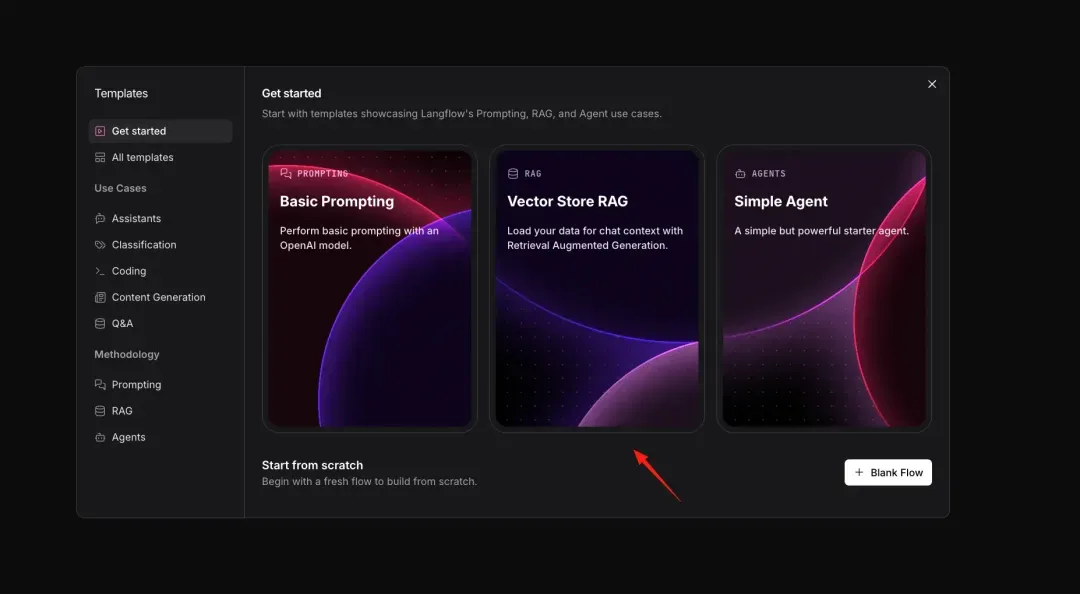
Choose Milvus as your default vector database.
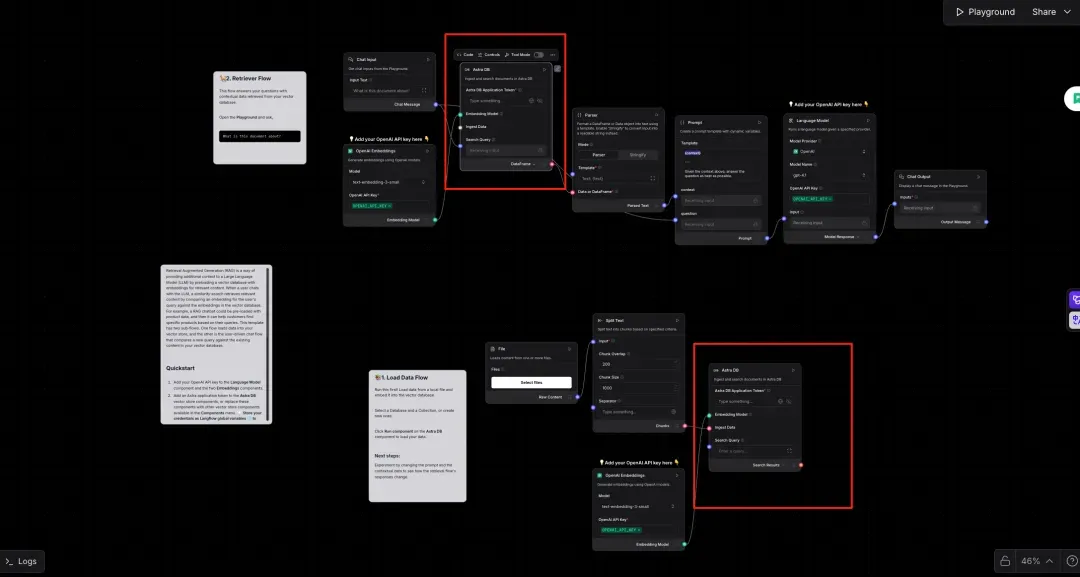
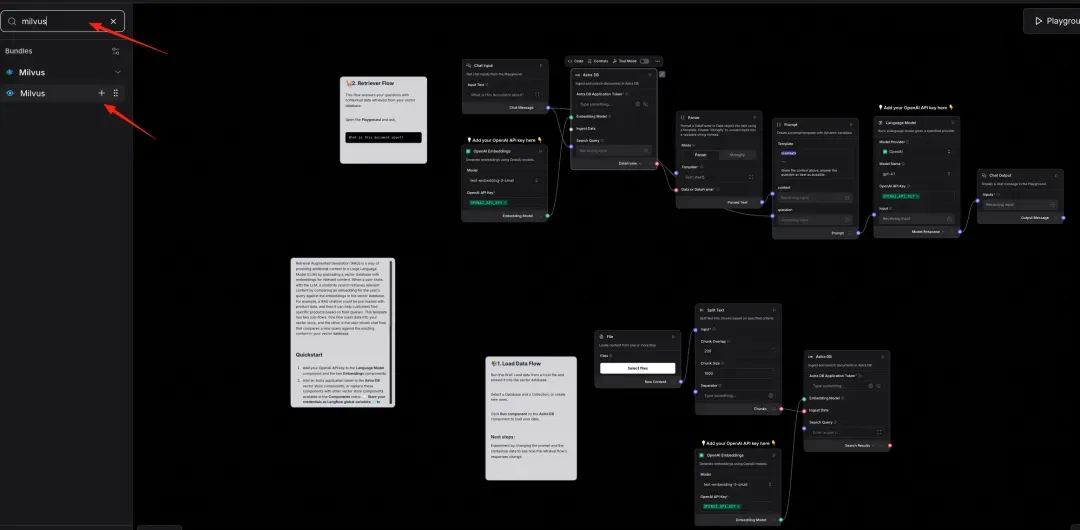
In the left panel, search for “Milvus” and add it to your flow.
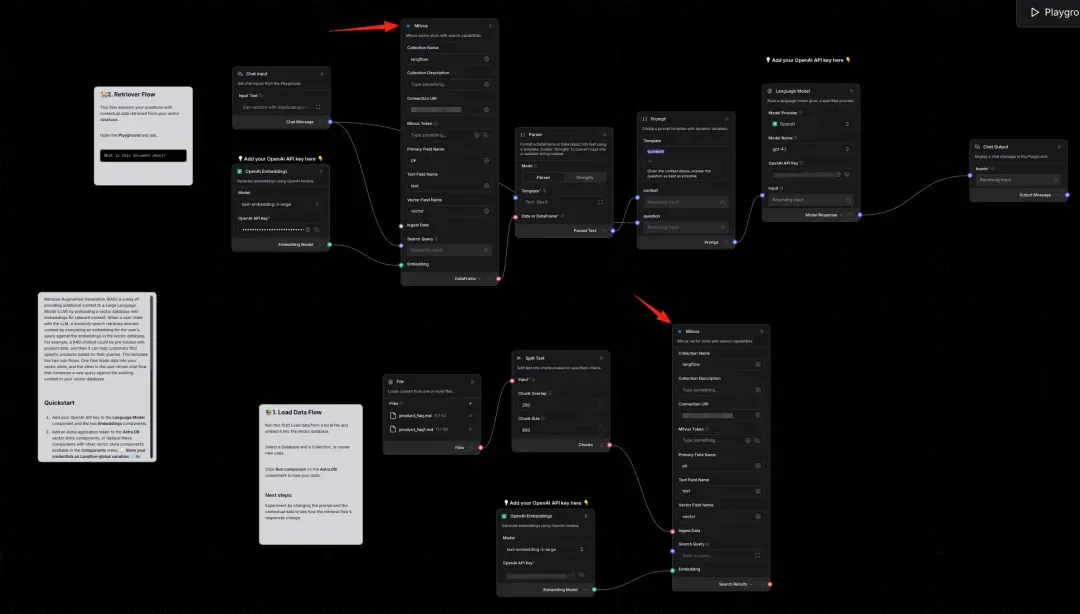
Configure Milvus connection details. Leave other options as the default for now.
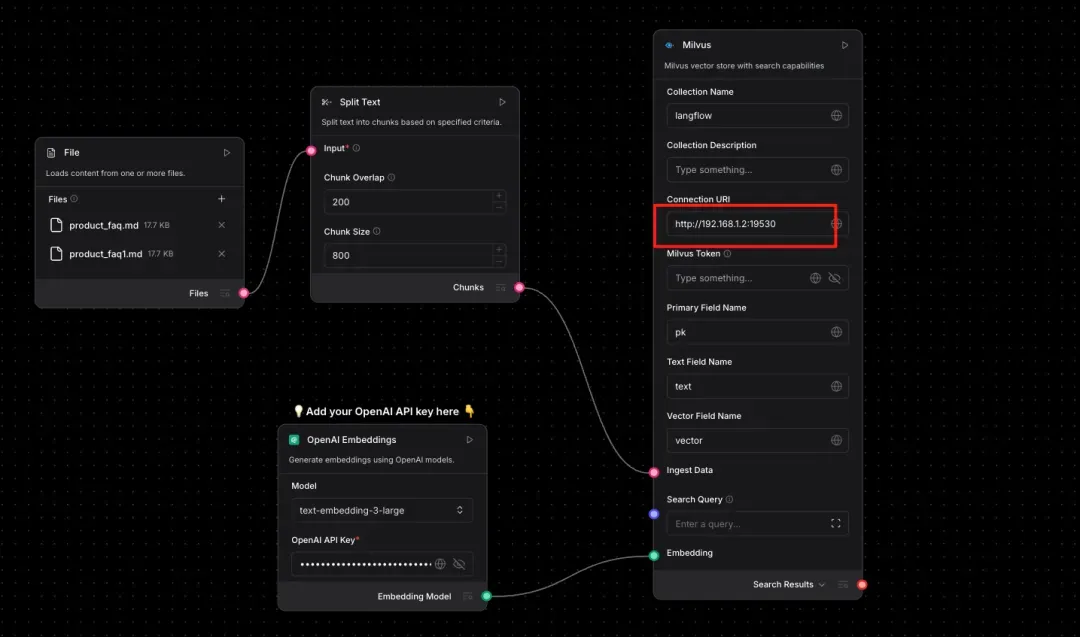
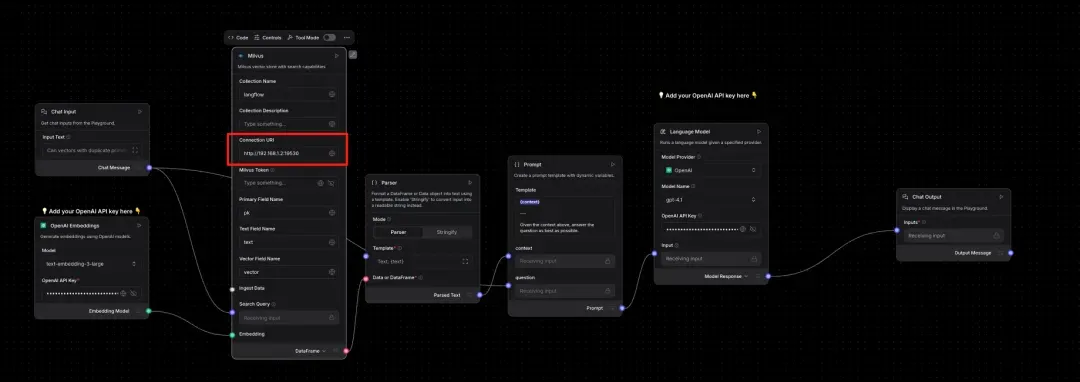
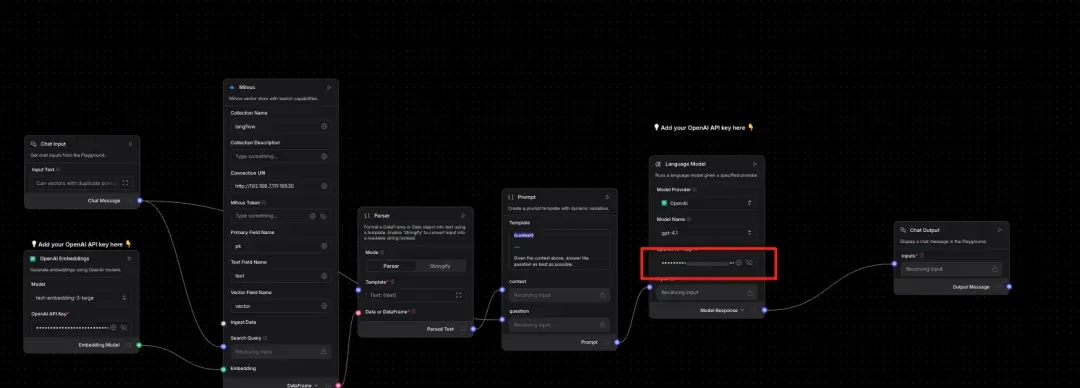
Add your OpenAI API key to the relevant node.
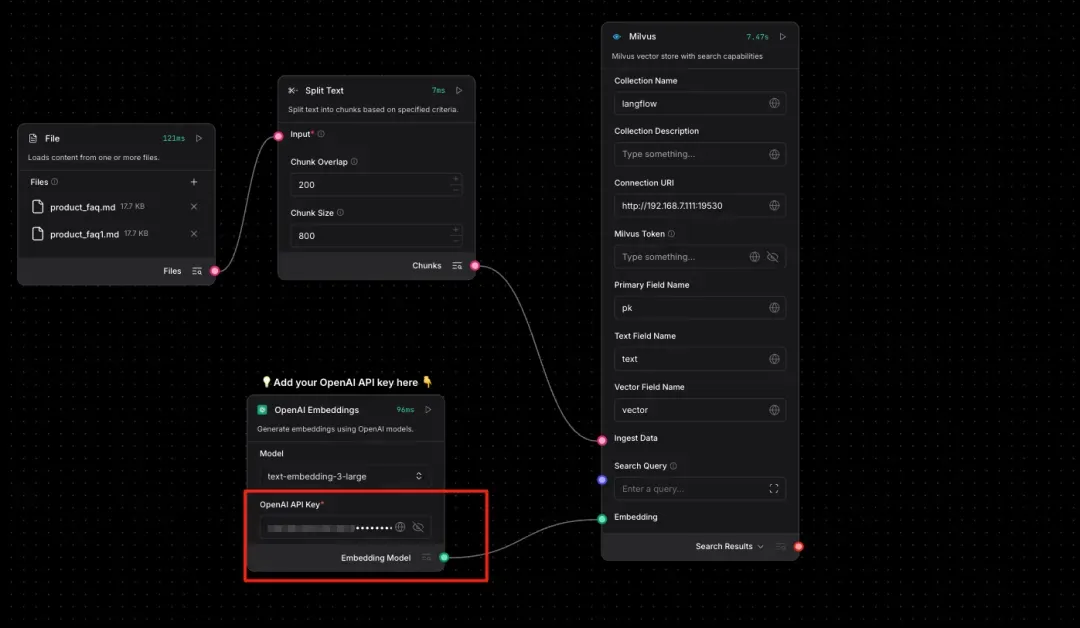
Step 6. Prepare Test Data
Note: Use the official FAQ for Milvus 2.6 as the test data.
https://github.com/milvus-io/milvus-docs/blob/v2.6.x/site/en/faq/product_faq.md
Step 7. Phase One Testing
Upload your dataset and ingest it into Milvus. Note: Langflow then converts your text into vector representations. You must upload at least two datasets, or the embedding process will fail. This is a known bug in Langflow’s current node implementation.
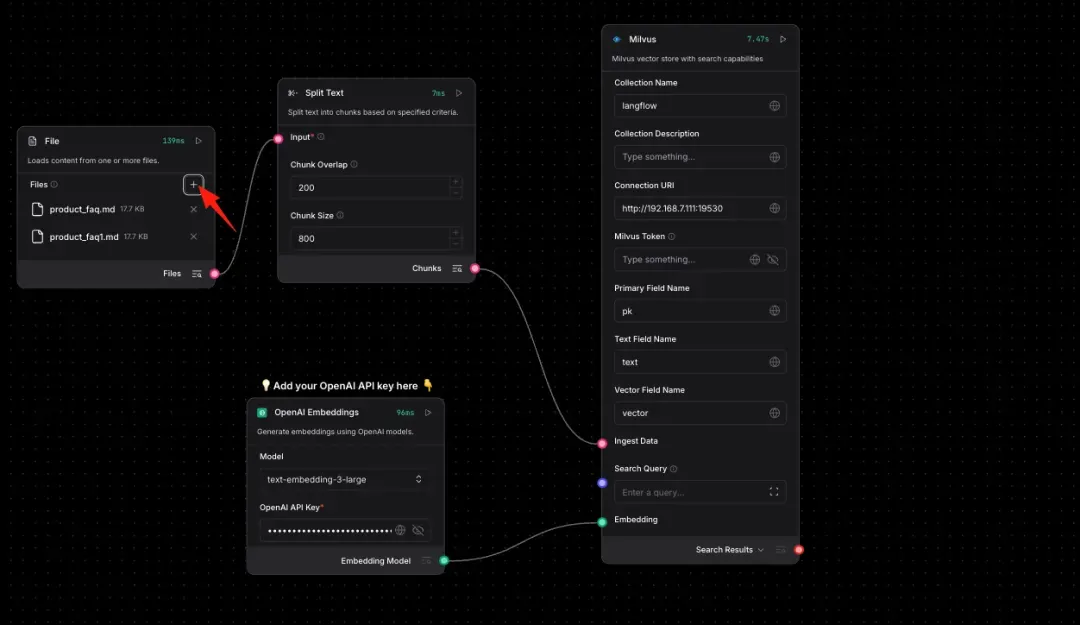
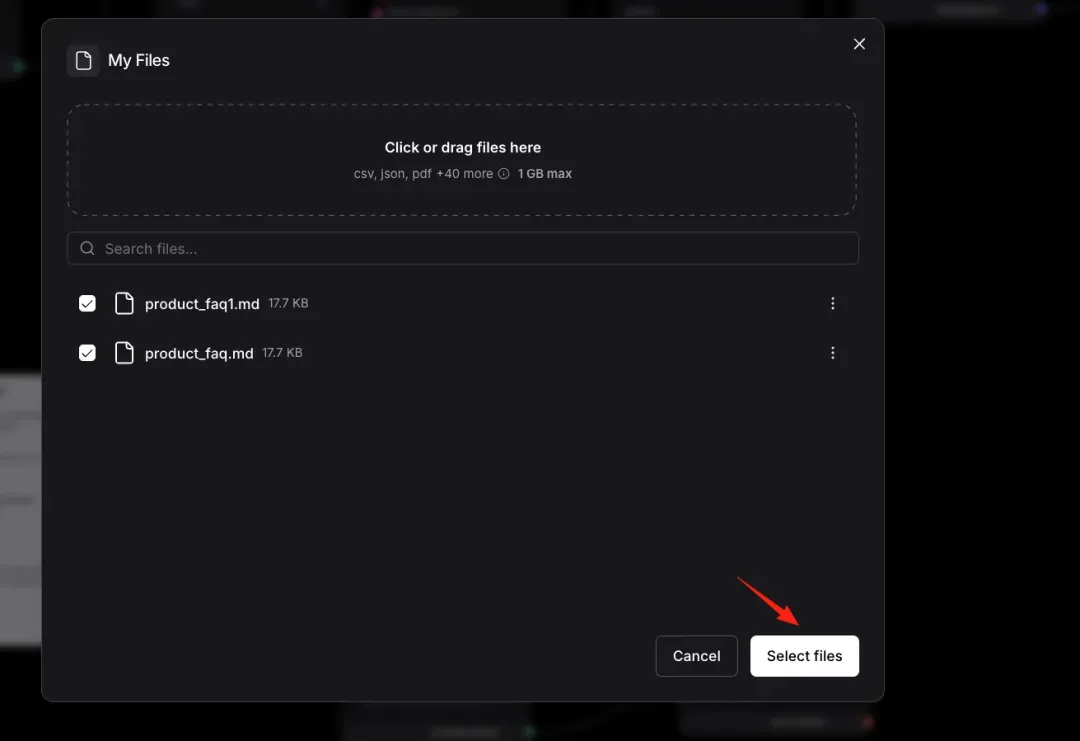
Check the status of your nodes.
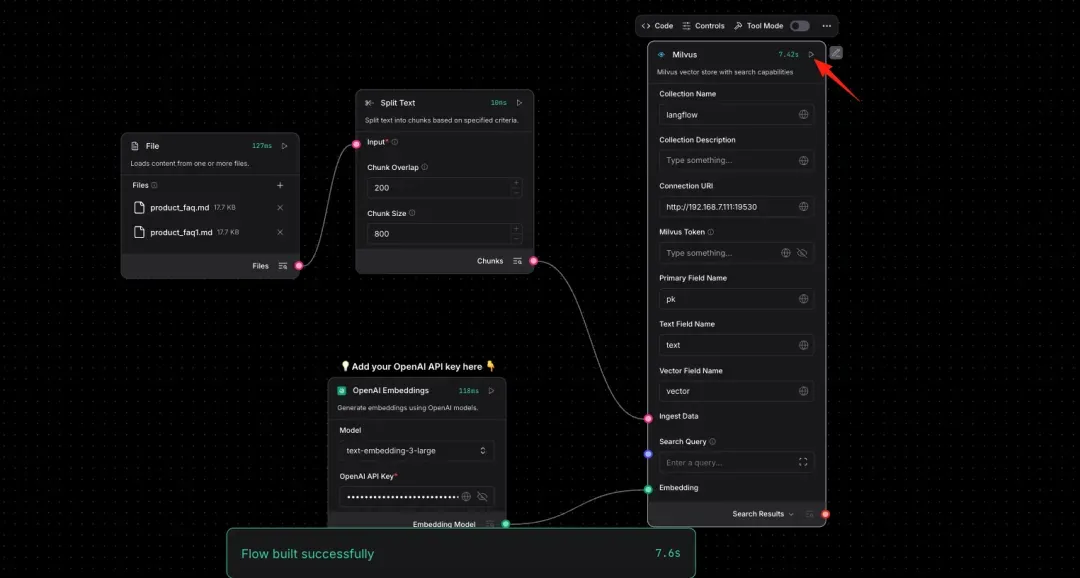
Step 8. Phase Two Testing
Step 9. Run the Full RAG Workflow
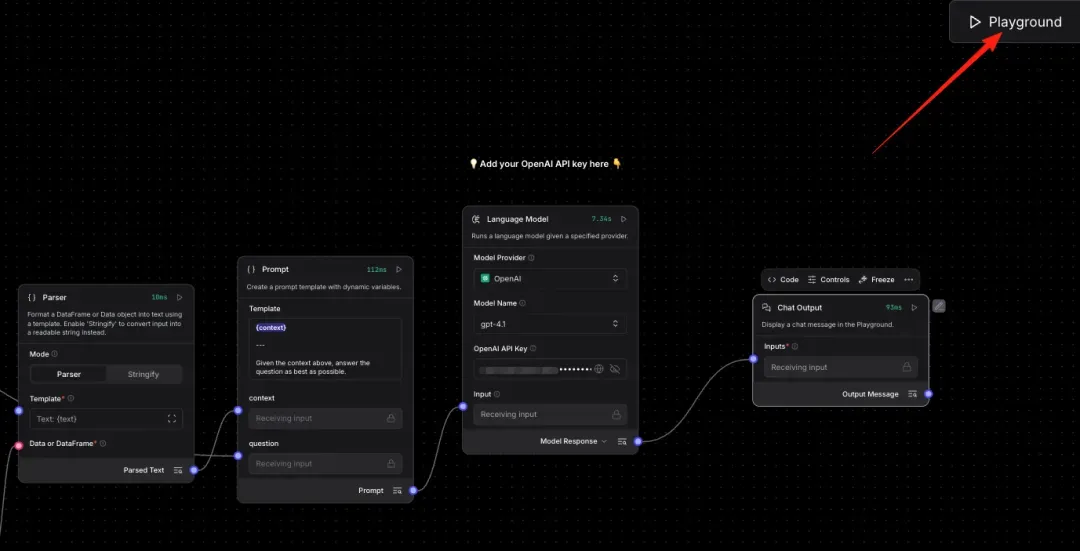
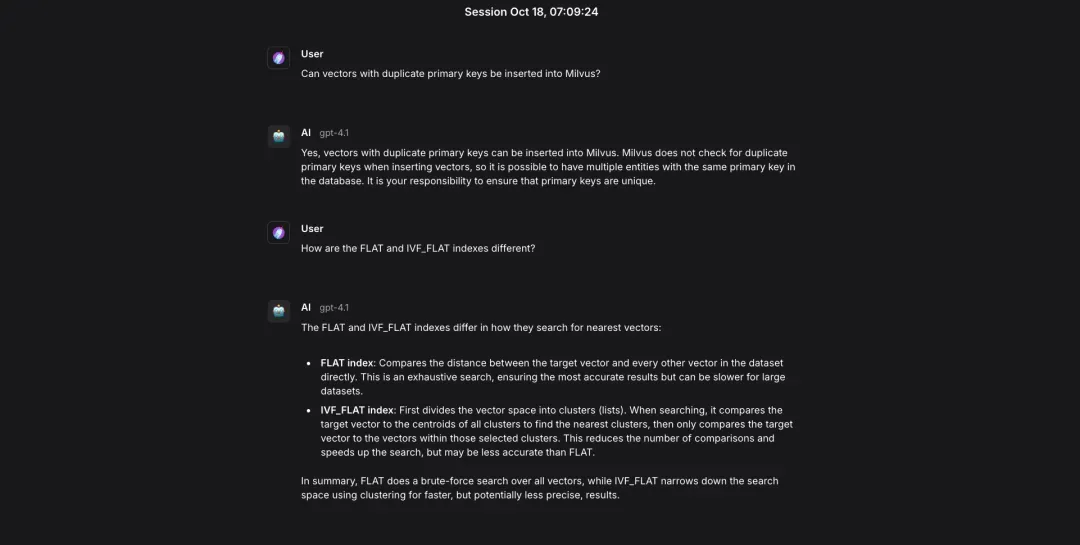
Conclusion
Building AI workflows doesn’t have to be complicated. Langflow + Milvus makes it fast, visual, and code-light — a simple way to enhance RAG without heavy engineering effort.
Langflow’s drag-and-drop interface makes it a suitable choice for teaching, workshops, or live demos, where you need to demonstrate how AI systems work in a clear and interactive manner. For teams seeking to integrate intuitive workflow design with enterprise-grade vector retrieval, combining Langflow’s simplicity with Milvus’s high-performance search delivers both flexibility and power.
👉 Start building smarter RAG workflows with Milvus today.
Have questions or want a deep dive on any feature? Join our Discord channel or file issues on GitHub. You can also book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
- What is Langflow?
- Hands-on Demo: How to Build a RAG Workflow with Langflow and Milvus
- Prerequisites:
- Step 1. Deploy Milvus Vector Database
- Step 2. Create a Python Virtual Environment
- Step 3. Install the Latest Packages
- Step 4. Launch Langflow
- Step 5. Configure the RAG Template
- Step 6. Prepare Test Data
- Step 7. Phase One Testing
- Step 8. Phase Two Testing
- Step 9. Run the Full RAG Workflow
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



