Full-Text Search in Milvus - What's Under the Hood
Introduction
While dense embedding retrieval excels at semantic search, full-text search algorithms like BM25 continue to play an important role in retrieval tasks, complementing dense embedding approaches with their predictability and ability to handle specialized terminology.
Since version 2.5, Milvus introduced built-in support for full-text search with the Sparse-BM25 approach, allowing users to easily integrate this capability into their search pipelines without the need for a separate search engine. In this blog, we will unveil how Sparse-BM25 works in Milvus.
The Famous BM25 Ranking Algorithm
BM25, short for Best Match 25, is a relevance ranking algorithm, designed to improve the TF-IDF (Term Frequency-Inverse Document Frequency) algorithm.
Given a set of documents, this is how we compute the BM25 relevance score between a query and an arbitrary document :
Here are some key points:
Term Frequency ( ): number of occurrences of the term t in document D. is a saturation argument to prevent words that occur too frequently from dominating the score.
Inverse Document Frequency ( ): measures the importance of a term. The fewer documents it appears in, the more important BM25 thinks it is. is the total number of documents in the corpus, is the number of documents that contain the word .
Document Length Normalization: TF-IDF tends to rank longer documents higher since they are more likely to contain query terms. BM25 reduces this bias by normalizing with average document length. can be used to tune normalization strength. is the length of the document (total number of terms), is the average document length of all documents.
Compared to TF-IDF, BM25 introduces two important optimizations: TF Saturation and Document Length Normalization. Such mechanisms drastically improved ranking quality, making BM25 the go-to algorithm of full-text search for decades.
Computing BM25 using Sparse Vector
We introduced support for Sparse Vector in Milvus 2.4. Unlike a dense vector, which has up to thousands of dimensions and most dimensions have a non-zero value, a sparse vector typically has tens of thousands or more dimensions, where the value of most dimensions is zero.
In ultra-high-dimensional space, the “curse of dimensionality” renders traditional distance metrics like Euclidean and Cosine ineffective. As the number of dimensions increases, the distance between the nearest and farthest vectors becomes nearly identical, making these metrics unreliable (for those who are interested, read The Curse of Dimensionality in Machine Learning). Due to that, Inner Product, or IP, becomes the only usable metric type for sparse vectors.
To understand how Milvus supports BM25 with a sparse vector approach, let’s transform the BM25 formula by replacing the right hand side with :
So the BM25 formula is now:
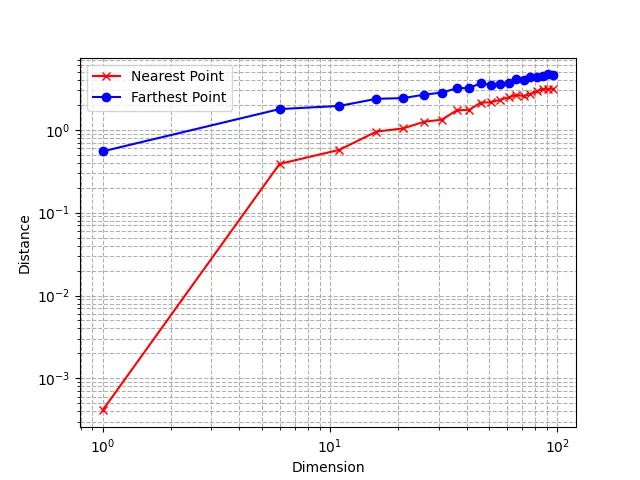
For those who know IP metric, does this look familiar to you? This is exactly the equation of IP distance for sparse vectors. Let’s see how this works with a concrete example:
Assume we have a set of documents, with one of them being I love Milvus!. After tokenization and lowercasing, we have the document’s TF value for each term, represented as a sparse vector: {i: 1, love: 1, milvus: 1}. We can then apply and transform it into:
{i: f(1), love: f(1), milvus: f(1)}
This will be the document vector.
For a query like Who loves Milvus?. Again, we first apply tokenization, lowercasing and stemming, and got query token list [who, love, milvus]. Apply the function and we can transform it into
{who: IDF(who), love: IDF(love), milvus: IDF(milvus)}
This will be our query vector.
The Inner Product of the document vector and query vector is:
Which is exactly the BM25 score of the query Who loves Milvus? and document I love Milvus!.
If we can encode the documents into sparse vectors and insert them into Milvus, then we can leverage Milvus’ sparse vector index to perform BM25 search. Sounds good? Well, not quite yet:
The calculation of requires , which is a global statistics value and constantly changing overtime as new documents being inserted and old documents being deleted. After we added new documents, the previously inserted document vector values become skewed, leading to inaccurate result!
There is much burden on the client side: the user of Milvus must have great knowledge of BM25, and must manage the term distribution statistics and perform vector encoding themselves.
These two shortcomings rendered this approach not suitable for serious production use cases. So we developed something better!
A Better Approach - Dynamic Stats and Search Time Encoding
In Milvus 2.5, we designed a novel approach to tackle those problems.
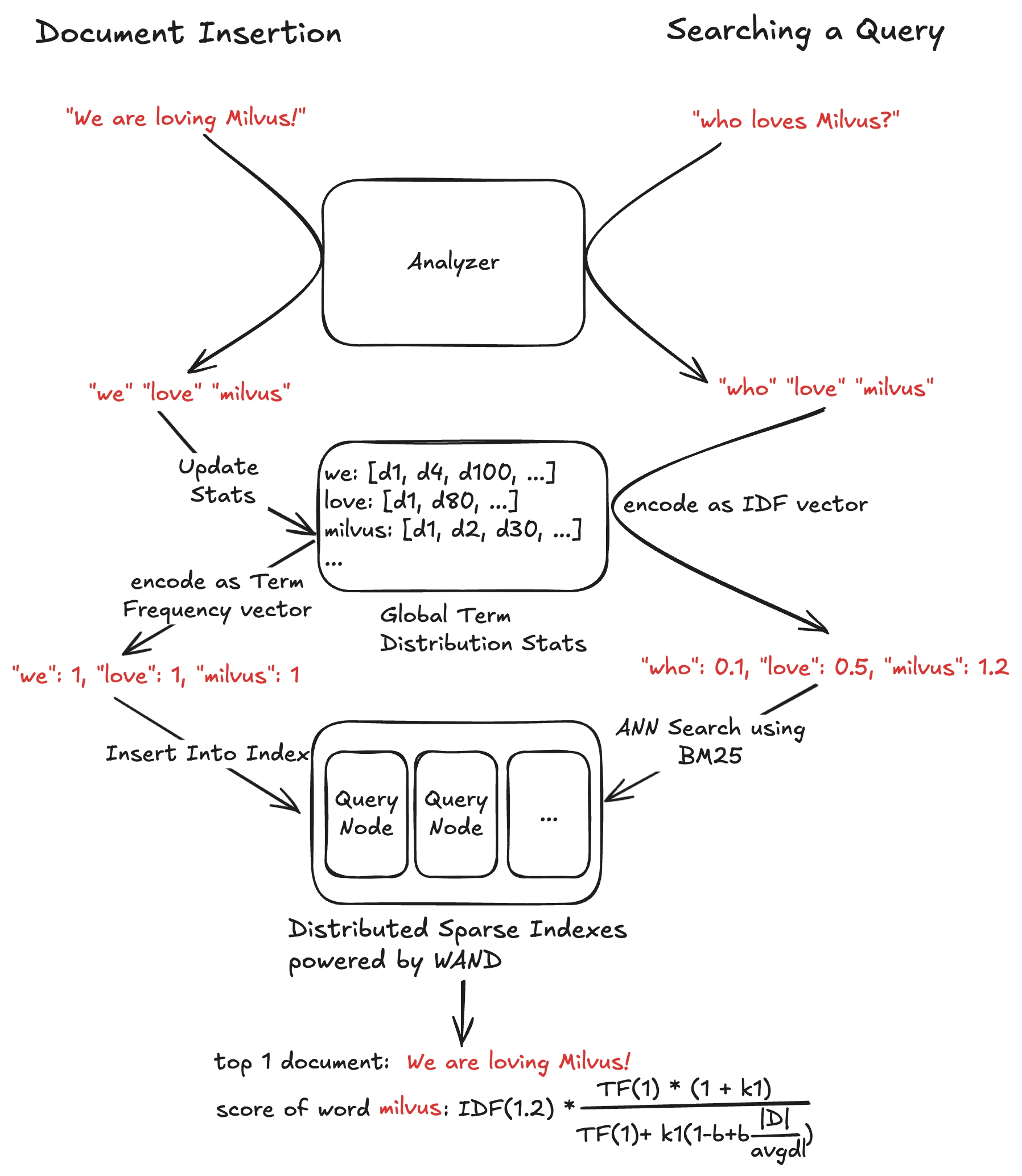
First, to deal with the ever-changing , instead of pre-computing , we only store the raw as the document vector. We add a new metric BM25 for the sparse vector field, and compute the BM25 score on the fly during query time. The BM25 score is still calculated with the query vector value and document vector value .
Secondly, users don’t need to pre-compute the sparse vector anymore. Users only need to provide the documents in raw text during ingestion or search. Milvus is responsible for processing the text into tokens with stop-word removal and stemming, and maintain a global term distribution statistics across the corpus that is required to compute both and .
At insertion time, texts are tokenized and converted into sparse vectors by Milvus and stored in a sparse vector field. At search time, Milvus encodes queries as vector based on the global stats and sends it to QueryNode along with a realtime to perform Sparse-BM25 search.
Full-Text Search Demo with PyMilvus
With this new feature, performing full-text search in Milvus is straightforward. Let’s walk through an example using PyMilvus, the official Python client for Milvus.
Step 1: Define a Collection Schema
First, we need to create a collection and define fields for the raw text data and the encoded document sparse vectors (we only need to ingest raw text data, the sparse vector is computed by Milvus internally).
First, we define a collection schema with fields for the raw text (document) and the sparse vector (sparse). Note that we also define a Function in the schema, which tells Milvus to automatically convert ingested raw text to sparse vector used for BM25 scoring.
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri="http://localhost:19530")
# Define a schema
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="document", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True)
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
# Add BM25 function mapping text to sparse vector
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["document"],
output_field_names=["sparse"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
💡 Make sure enable_analyzer=True is set for the text field to be searchable using BM25. You can also configure a custom analyzer if needed—see the Analyzer documentation for details.
Step 2: Create an Index
Just like dense vector fields, sparse vector fields also require an index. Here, we create an automatic index using the BM25 metric.
# Prepare the index
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="AUTO_INDEX",
metric_type="BM25"
)
# Create the collection (Milvus will automatically load it)
client.create_collection(
collection_name="hello_bm25",
schema=schema,
index_params=index_params
)
Step 3: Insert Data (Raw Text Only)
With the schema and index ready, we can now insert raw text into the collection. There’s no need to provide the sparse vector—Milvus generates it automatically using the BM25 function.
# Insert documents
entities = [
{"document": "Artificial intelligence was founded ..."},
{"document": "Alan Turing was the first person to ..."},
{"document": "Born in Maida Vale, London, Turing ..."},
]
client.insert("hello_bm25", entities)
Step 4: Perform a Full-Text Search
You can now search using natural language queries!
# Example: Search for "Artificial Intelligence"
client.search(
collection_name="hello_bm25",
data=["Artificial Intelligence"],
anns_field="sparse",
limit=1,
output_fields=["document"]
)
That’s all, simple like that!
Conclusion
With built-in BM25 support, Milvus brings full-text search and vector search together in one unified engine. By handling tokenization, sparse vector encoding, and dynamic stats internally, it removes the cumbersome manual BM25 sparse vector computation outside of vector database.
We developed this feature to help you build advanced search applications with minimal effort. You can now combine full-text search with dense vector search and reranking function, building your own hybrid search. Check out the full tutorial to get started!
- Introduction
- The Famous BM25 Ranking Algorithm
- Computing BM25 using Sparse Vector
- A Better Approach - Dynamic Stats and Search Time Encoding
- Full-Text Search Demo with PyMilvus
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



