GPT-5 Review: Accuracy Up, Prices Down, Code Strong — But Bad for Creativity
After months of speculation, OpenAI has finally shipped GPT-5. The model isn’t the creative lightning strike that GPT-4 was, but for developers, especially those building agents and RAG pipelines, this release may quietly be the most useful upgrade yet.
TL;DR for builders: GPT-5 unifies architectures, supercharges multimodal I/O, slashes factual error rates, extends context to 400k tokens, and makes large-scale usage affordable. However, the creativity and literary flair have taken a noticeable step back.
What’s New Under the Hood?
Unified core — Merges GPT digital series with o-series reasoning models, delivering long-chain reasoning plus multimodal in a single architecture.
Full-spectrum multimodal — Input/output across text, image, audio, and video, all within the same model.
Massive accuracy gains:
gpt-5-main: 44% fewer factual errors vs. GPT-4o.gpt-5-thinking: 78% fewer factual errors vs. o3.
Domain skill boosts — Stronger in code generation, mathematical reasoning, health consultation, and structured writing; hallucinations reduced significantly.
Alongside GPT-5, OpenAI also released three additional variants, each optimized for different needs:

| Model | Description | Input / $ per 1M tokens | Output / $ per 1M tokens | Knowledge Update |
|---|---|---|---|---|
| gpt-5 | Main model, long-chain reasoning + full multimodal | $1.25 | $10.00 | 2024-10-01 |
| gpt-5-chat | Equivalent to gpt-5, used in ChatGPT conversations | — | — | 2024-10-01 |
| gpt-5-mini | 60% cheaper, retains ~90% of programming performance | $0.25 | $2.00 | 2024-05-31 |
| gpt-5-nano | Edge/offline, 32K context, latency <40ms | $0.05 | $0.40 | 2024-05-31 |
GPT-5 broke records across 25 benchmark categories — from code repair to multimodal reasoning to medical tasks — with consistent accuracy improvements.
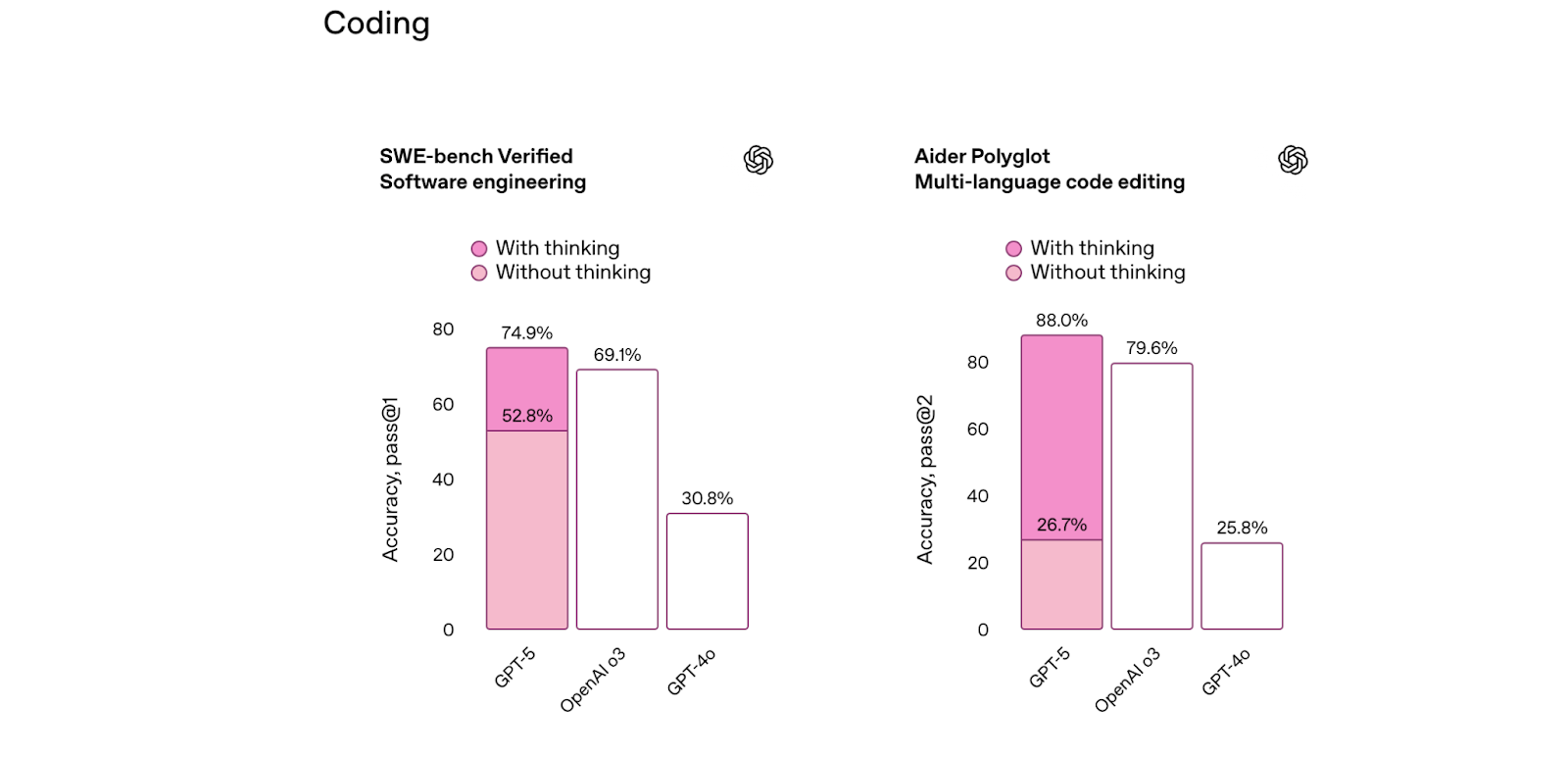
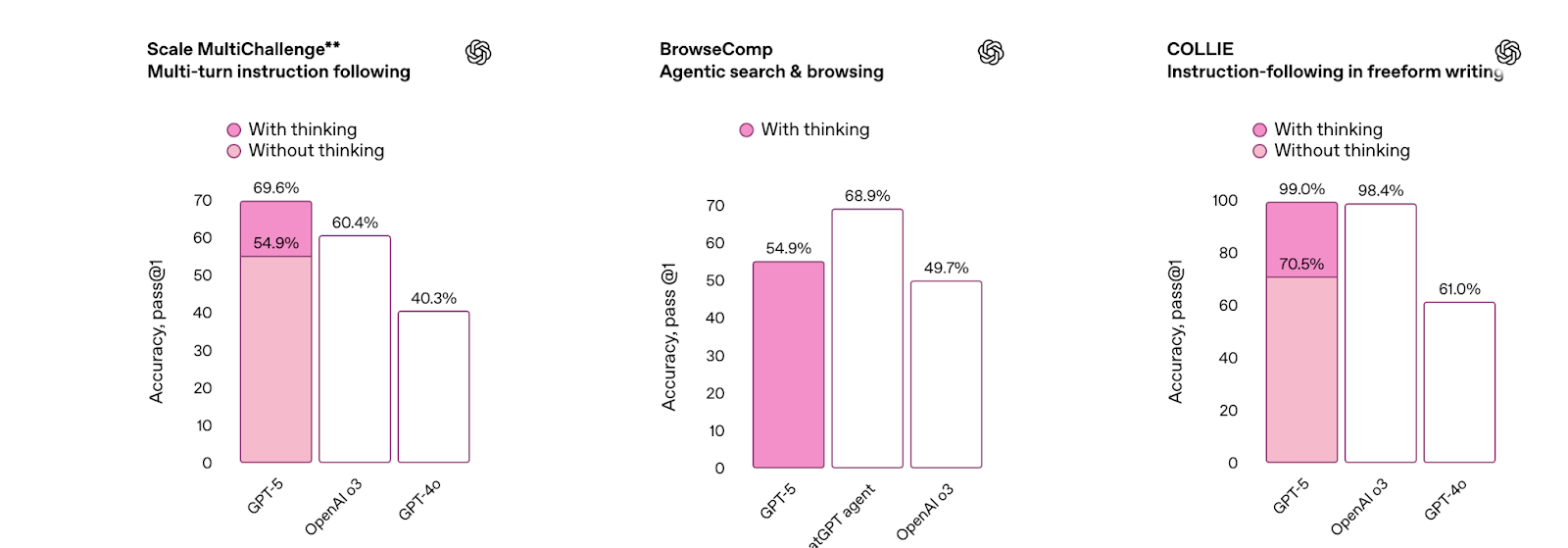
Why Developers Should Care — Especially for RAG & Agents
Our hands-on tests suggest this release is a quiet revolution for Retrieval-Augmented Generation and agent-driven workflows.
Price cuts make experimentation viable — API input cost: 10.
A 400k context window (vs. 128k in o3/4o) allows you to maintain state across complex multi-step agent workflows without context chopping.
Fewer hallucinations & better tool use — Supports multi-step chained tool calls, handles complex non-standard tasks, and improves execution reliability.

Not Without Flaws
Despite its technical advances, GPT-5 still shows clear limits.
At launch, OpenAI’s keynote featured a slide that bizarrely calculated 52.8 > 69.1 = 30.8, and in our own tests, the model confidently repeated the textbook-but-wrong “Bernoulli effect” explanation for airplane lift—reminding us it’s still a pattern learner, not a true domain expert.
While STEM performance has sharpened, creative depth has slipped. Many long-time users note a decline in literary flair: poetry feels flatter, philosophical conversations less nuanced, and long-form narratives more mechanical. The trade-off is clear—higher factual accuracy and stronger reasoning in technical domains, but at the expense of the artful, exploratory tone that once made GPT feel almost human.
With that in mind, let’s see how GPT-5 actually performs in our hands-on tests.
Coding Tests
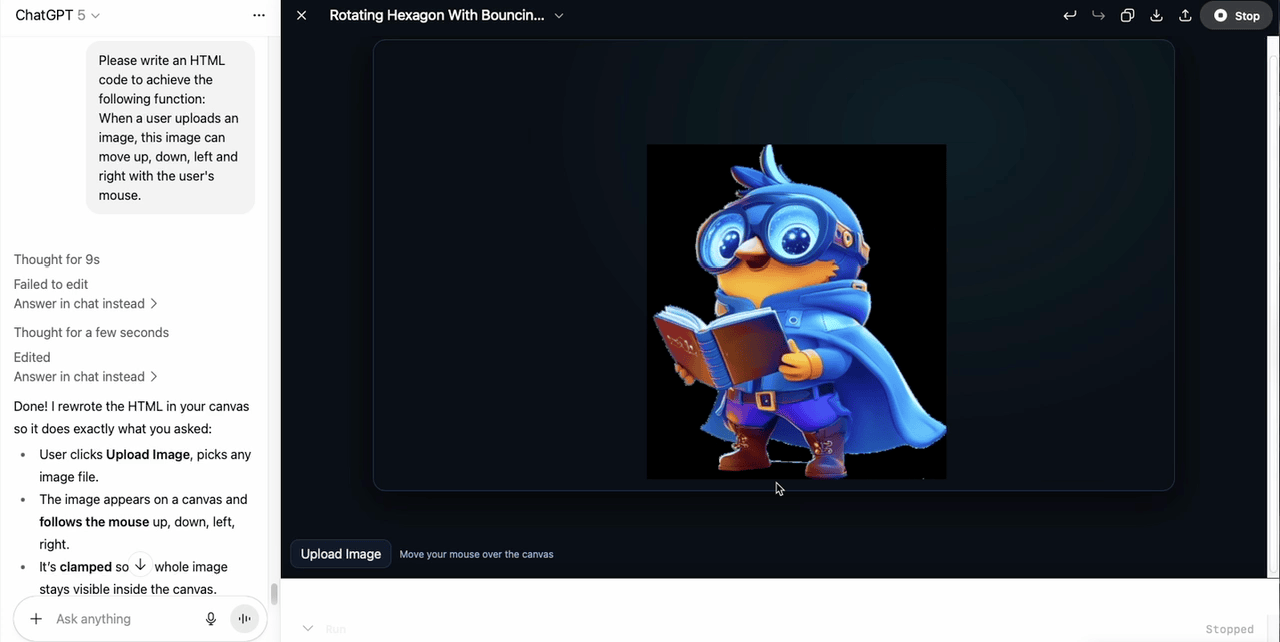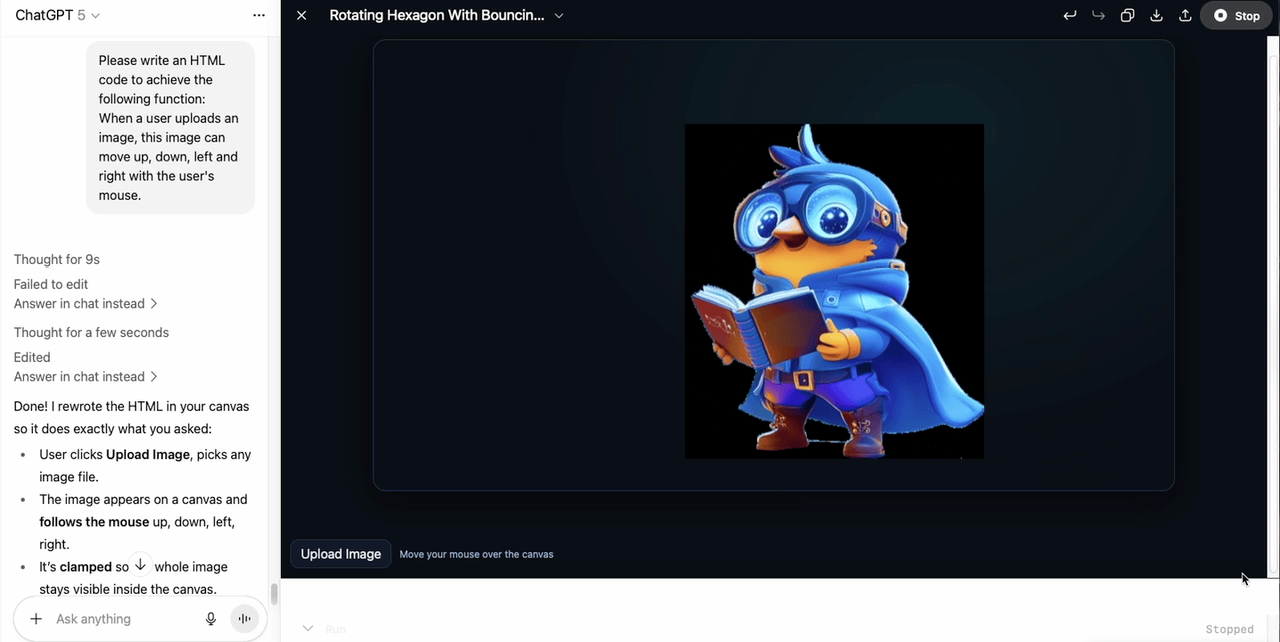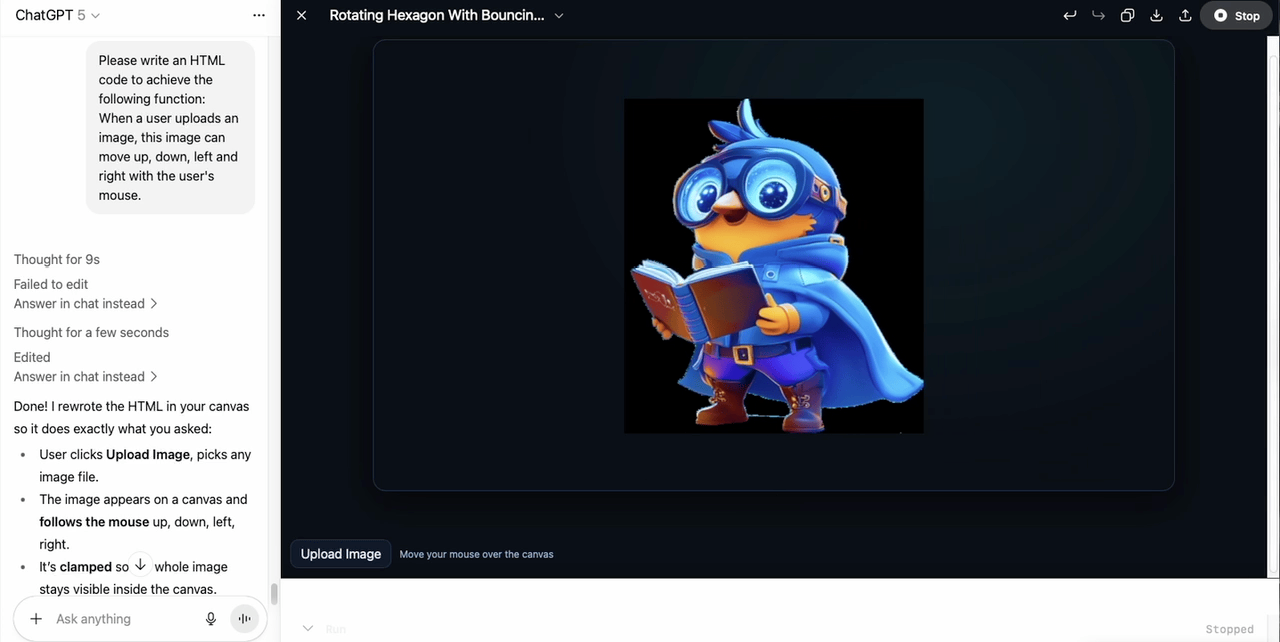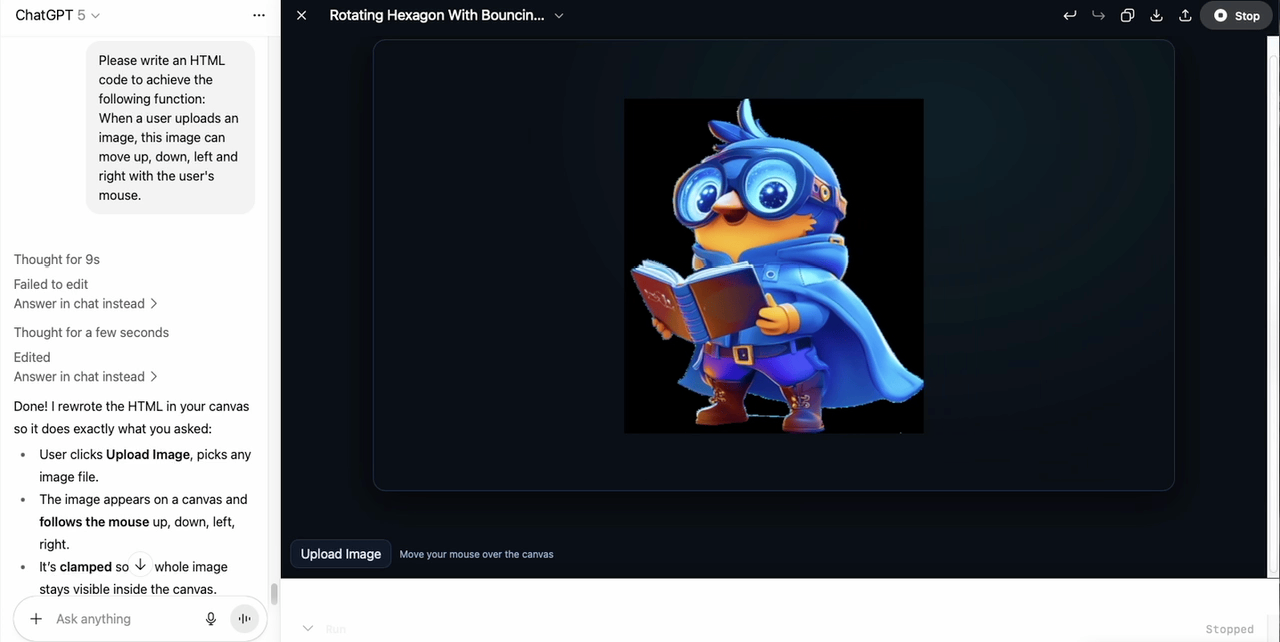
I started with a simple task: write an HTML script that allows users to upload an image and move it with the mouse. GPT-5 paused for about nine seconds, then produced working code that handled the interaction well. It felt like a good start.
The second task was harder: implement polygon–ball collision detection inside a rotating hexagon, with adjustable rotation speed, elasticity, and ball count. GPT-5 generated the first version in around thirteen seconds. The code included all expected features, but it had bugs and wouldn’t run.
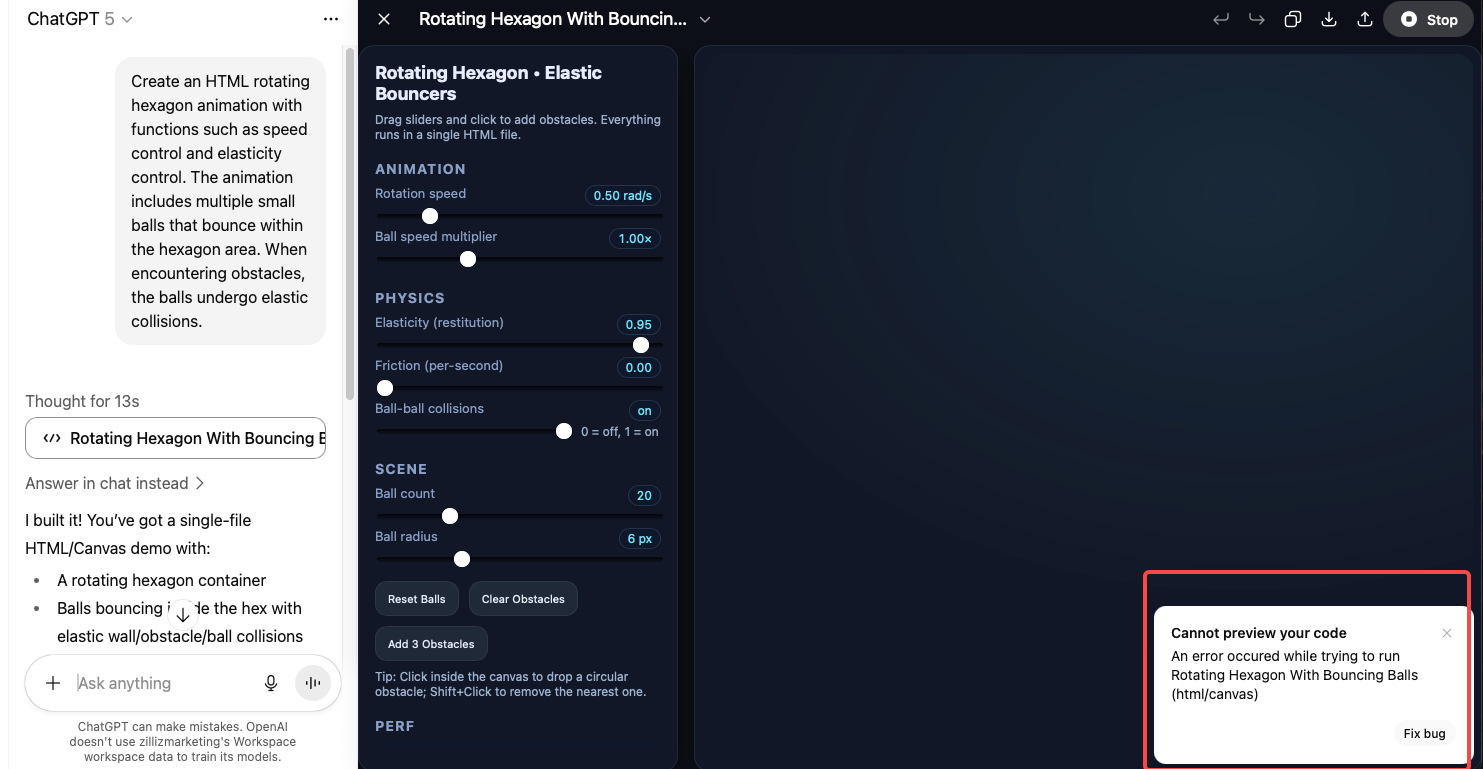
I then used the editor’s Fix bug option, and GPT-5 corrected the errors so the hexagon rendered. However, the balls never appeared — the spawn logic was missing or incorrect, meaning the core function of the program was absent despite the otherwise complete setup.
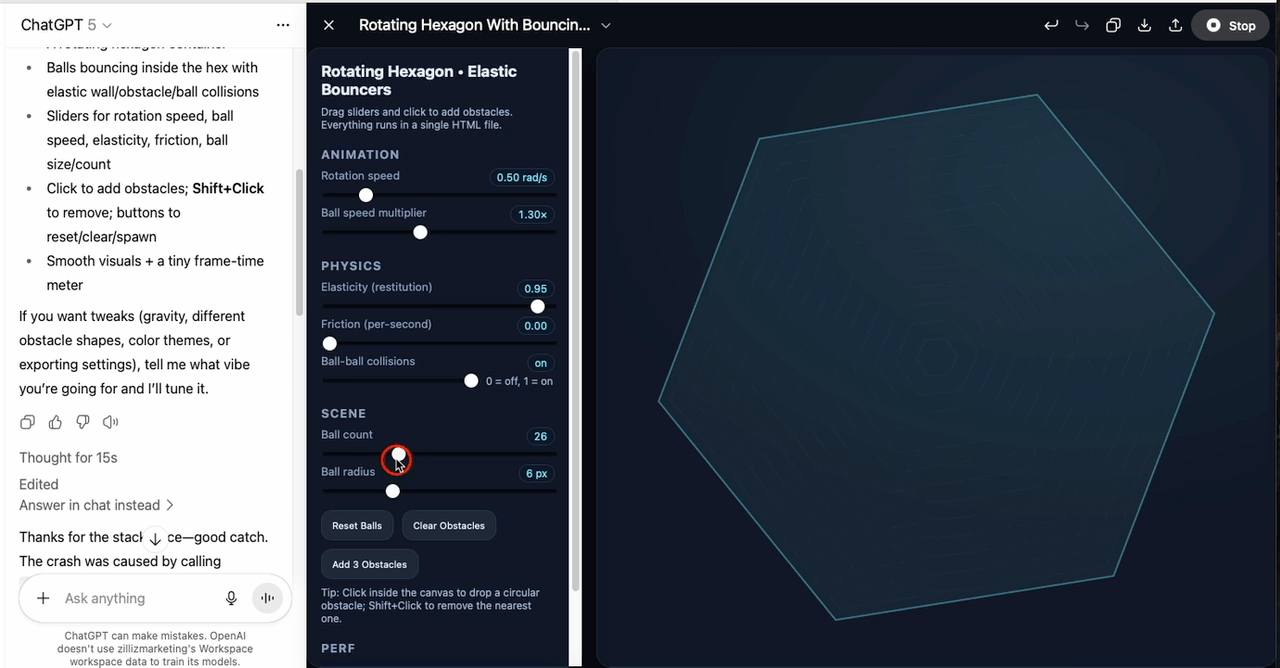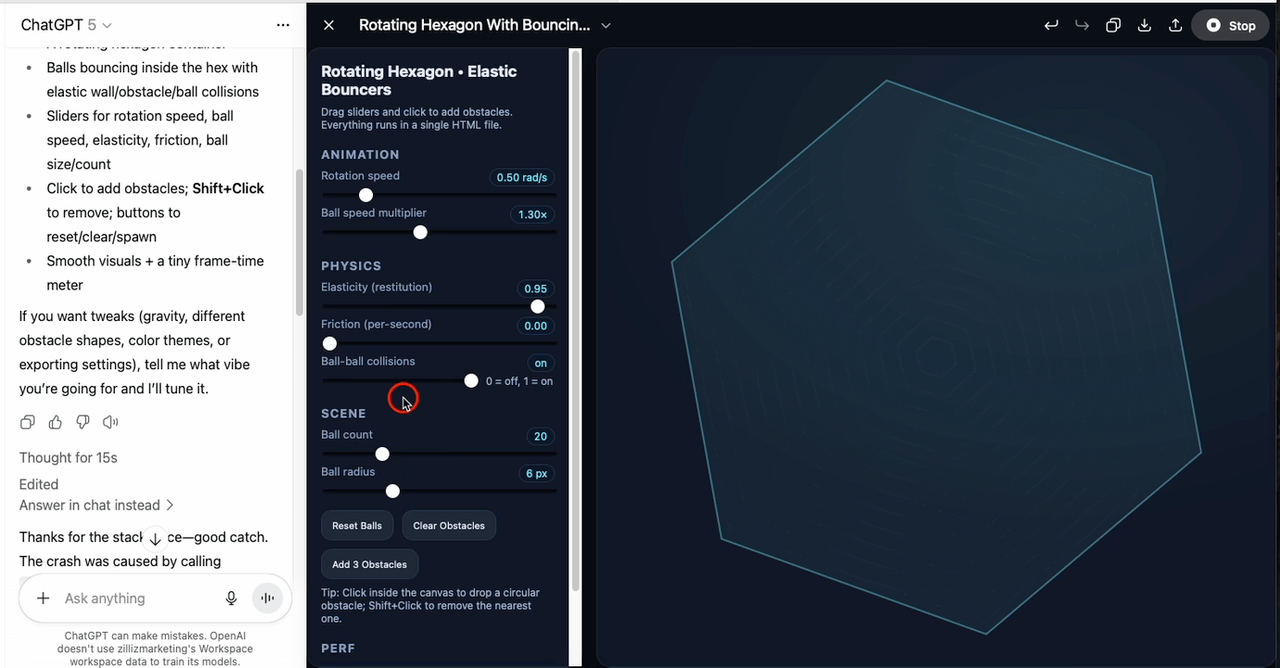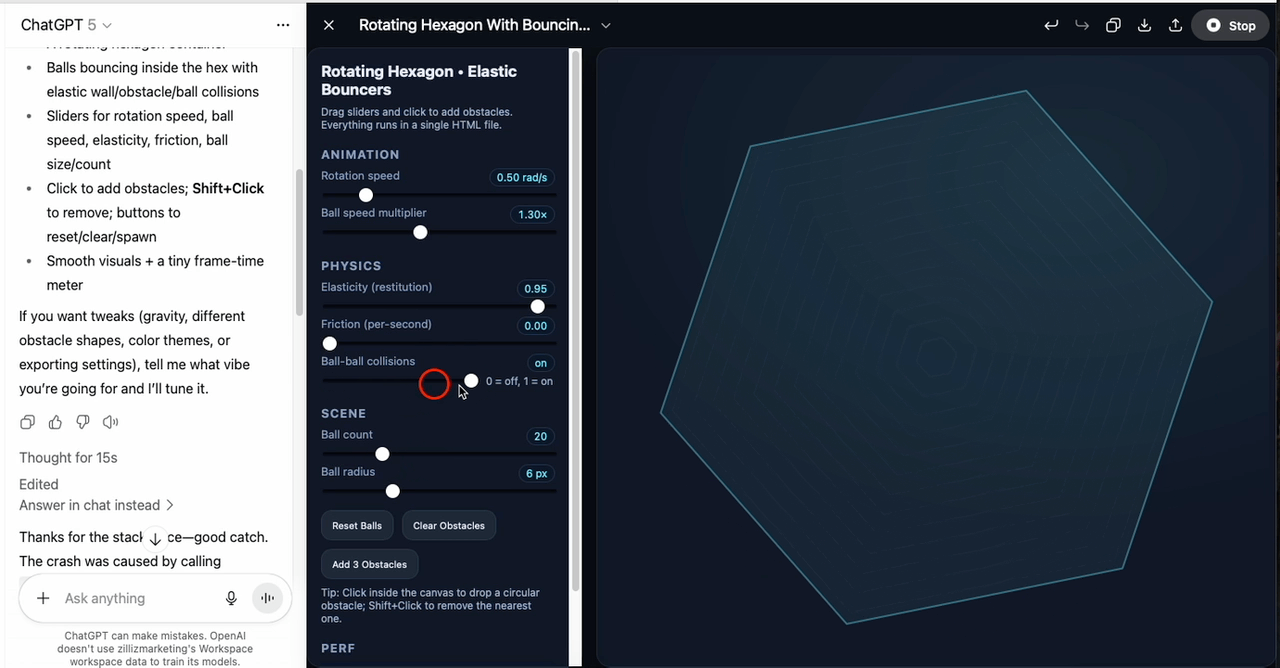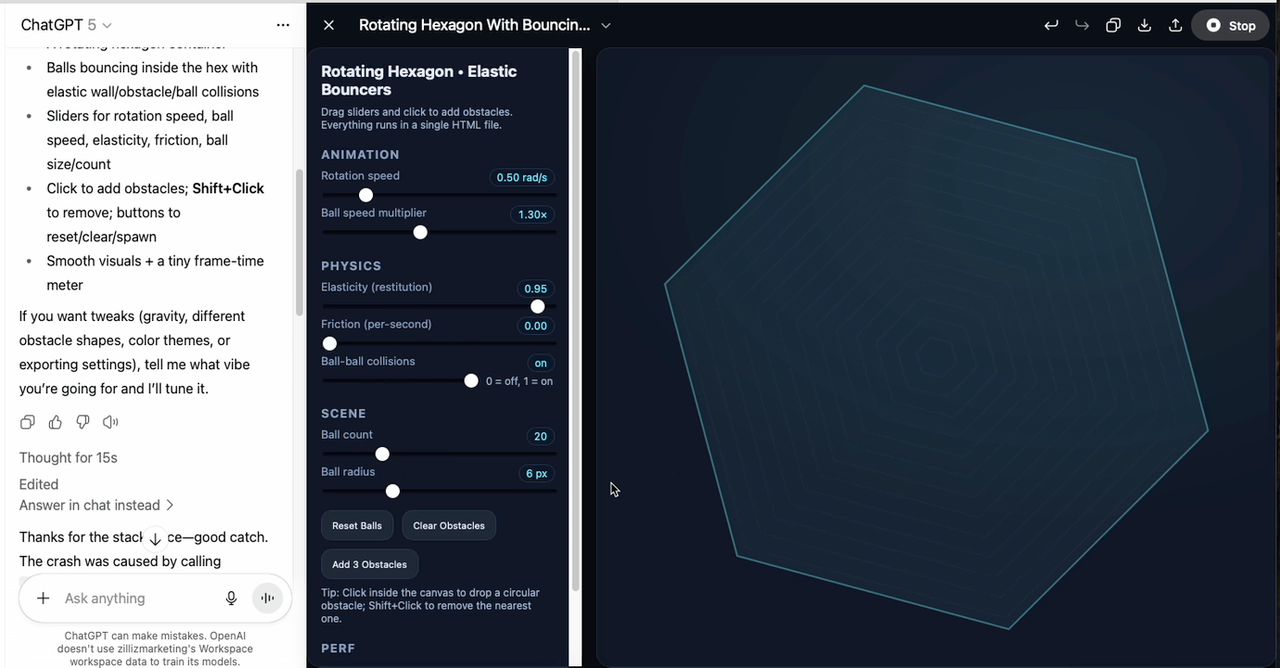
In summary, GPT-5 can produce clean, well-structured interactive code and recover from simple runtime errors. But in complex scenarios, it still risks omitting essential logic, so human review and iteration are necessary before deployment.
Reasoning Test
I posed a multi-step logic puzzle involving item colors, prices, and positional clues—something that would take most humans several minutes to solve.
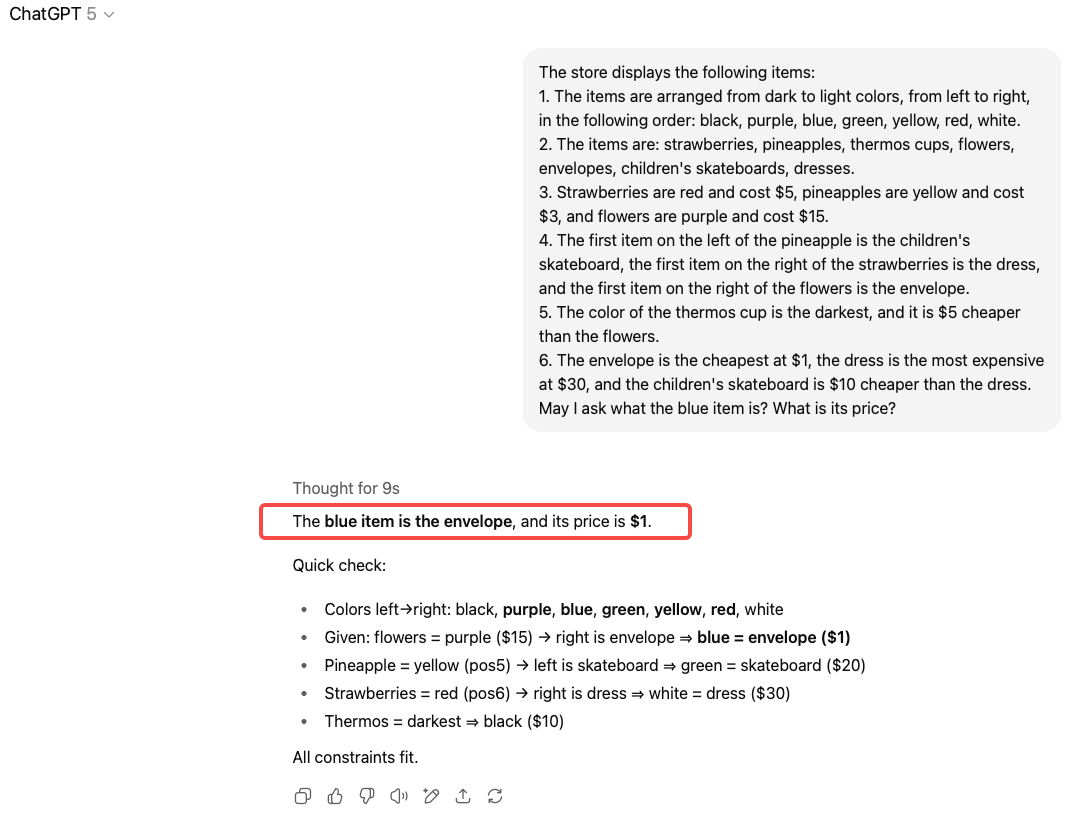
Question: What is the blue item and what is its price?
GPT-5 delivered the correct answer in just 9 seconds, with a clear and logically sound explanation. This test reinforced the model’s strength in structured reasoning and rapid deduction.
Writing Test
I often turn to ChatGPT for help with blogs, social media posts, and other written content, so text generation is one of the capabilities I care about most. For this test, I asked GPT-5 to create a LinkedIn post based on a blog about Milvus 2.6’s multilingual analyzer.

The output was well-organized and hit all the key points from the original blog, but it felt too formal and predictable—more like a corporate press release than something meant to spark interest on a social feed. It lacked the warmth, rhythm, and personality that make a post feel human and inviting.
On the upside, the accompanying illustrations were excellent: clear, on-brand, and perfectly aligned with Zilliz’s tech style. Visually, it was spot-on; the writing just needs a bit more creative energy to match.
Longer Context Window = Death of RAG and VectorDB?
We tackled this topic last year when Google launched Gemini 1.5 Pro with its ultra-long 10M-token context window. At the time, some people were quick to predict the end of RAG—and even the end of databases altogether. Fast-forward to today: not only is RAG still alive, it’s thriving. In practice, it’s become more capable and productive, along with vector databases like Milvus and Zilliz Cloud.
Now, with GPT-5’s expanded context length and more advanced tool-calling capabilities, the question has popped up again: Do we still need vector databases for context ingestion, or even dedicated agents/RAG pipelines?
The short answer: absolutely yes. We still need them.
Longer context is useful, but it’s not a replacement for structured retrieval. Multi-agent systems are still on track to be a long-term architectural trend—and these systems often need virtually unlimited context. Plus, when it comes to managing private, unstructured data securely, a vector database will always be the final gatekeeper.
Conclusion
After watching OpenAI’s launch event and running my own hands-on tests, GPT-5 feels less like a dramatic leap forward and more like a refined blend of past strengths with a few well-placed upgrades. That’s not a bad thing—it’s a sign of the architectural and data-quality limits large models are starting to encounter.
As the saying goes, severe criticism comes from high expectations. Any disappointment around GPT-5 mostly comes from the very high bar OpenAI set for itself. And really—better accuracy, lower prices, and integrated multimodal support are still valuable wins. For developers building agents and RAG pipelines, this may actually be the most useful upgrade so far.
Some friends have been joking about making “online memorials” for GPT-4o, claiming their old chat companion’s personality is gone forever. I don’t mind the change—GPT-5 might be less warm and chatty, but its direct, no-nonsense style feels refreshingly straightforward.
What about you? Share your thoughts with us—join our Discord, or join the conversation on LinkedIn and X.
- What’s New Under the Hood?
- Why Developers Should Care — Especially for RAG & Agents
- Not Without Flaws
- Coding Tests
- Reasoning Test
- Writing Test
- Longer Context Window = Death of RAG and VectorDB?
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word