Introducing the Milvus Sizing Tool: Calculating and Optimizing Your Milvus Deployment Resources
Introduction
Selecting the optimal configuration for your Milvus deployment is critical for performance optimization, efficient resource utilization, and cost management. Whether you’re building a prototype or planning a production deployment, properly sizing your Milvus instance can mean the difference between a smoothly running vector database and one that struggles with performance or incurs unnecessary costs.
To simplify this process, we’ve revamped our Milvus Sizing Tool, a user-friendly calculator that generates recommended resource estimations based on your specific requirements. In this guide, we’ll walk you through using the tool and provide deeper insights into the factors that influence the Milvus performance.
How to Use the Milvus Sizing Tool
It’s super easy to use this sizing tool. Simply follow the following steps.
Visit the Milvus Sizing Tool page.
Enter your key parameters:
Number of vectors and dimensions per vector
Index type
Scalar field data size
Segment size
Your preferred deployment mode
Review the generated resource recommendations
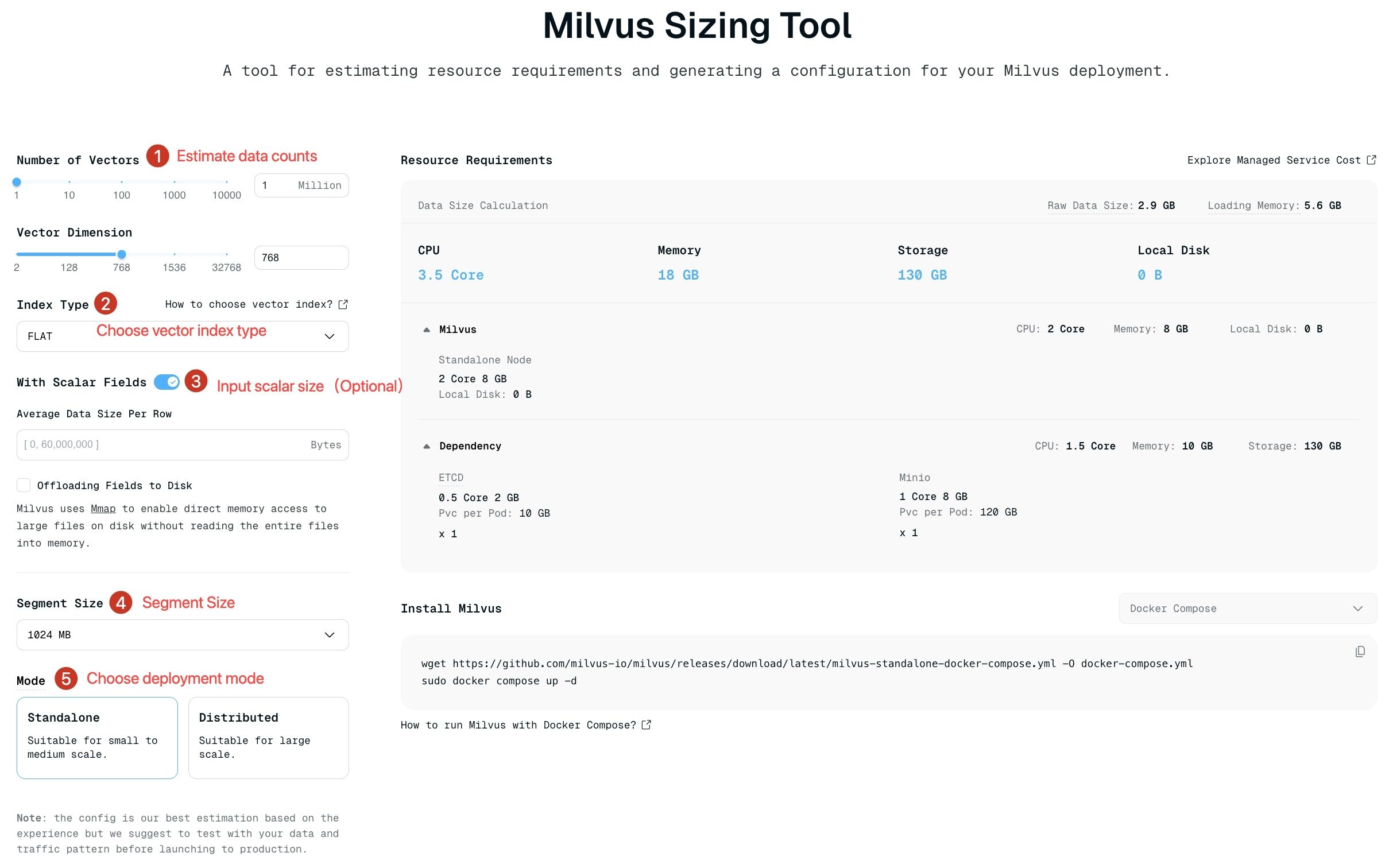 milvus sizing tool
milvus sizing tool
Let’s explore how each of these parameters impacts your Milvus deployment.
Index Selection: Balancing Storage, Cost, Accuracy, and Speed
Milvus offers various index algorithms, including HNSW, FLAT, IVF_FLAT, IVF_SQ8, ScaNN, DiskANN, and more, each with distinct trade-offs in memory usage, disk space requirements, query speed, and search accuracy.
Here’s what you need to know about the most common options:
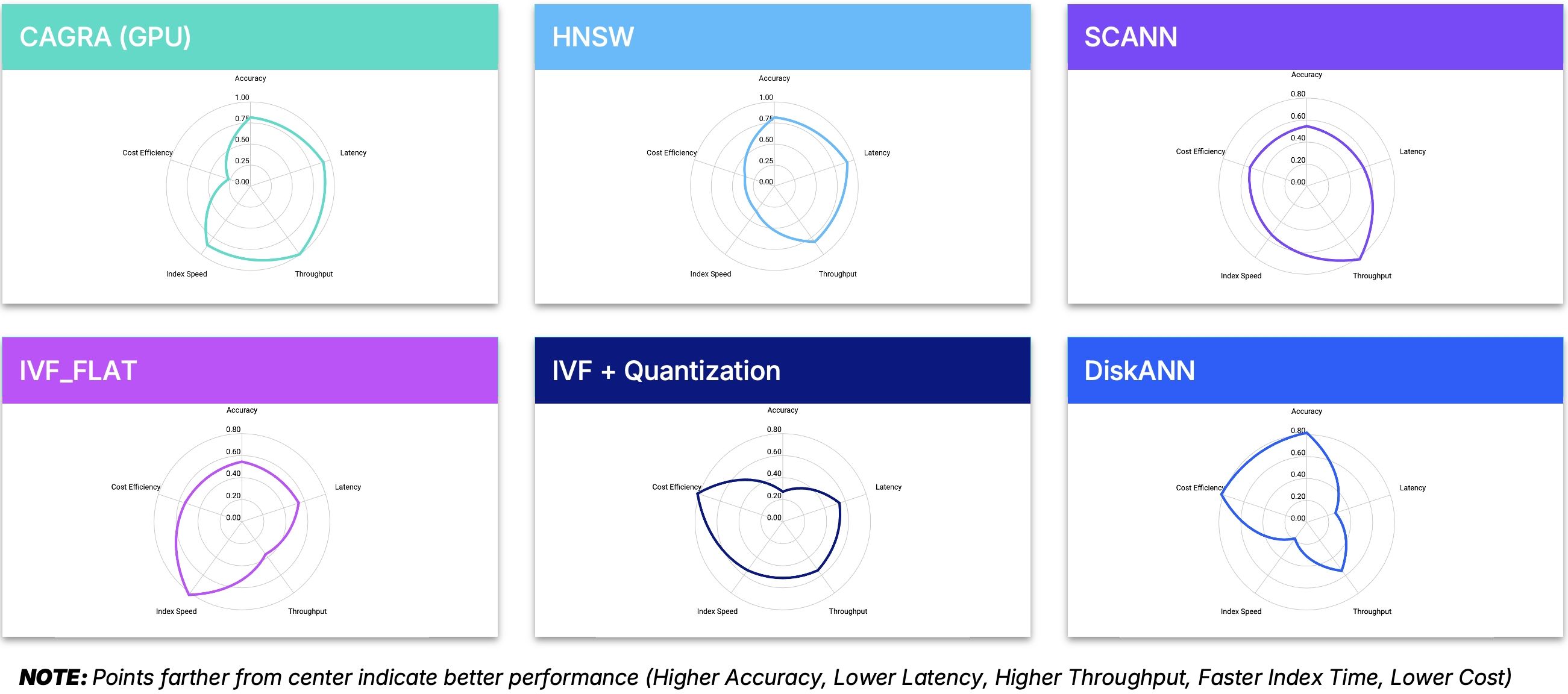 index
index
HNSW (Hierarchical Navigable Small World)
Architecture: Combines skip lists with Navigable Small Worlds (NSWs) graphs in a hierarchical structure
Performance: Very fast querying with excellent recall rates
Resource Usage: Requires the most memory per vector (highest cost)
Best For: Applications where speed and accuracy are critical and memory constraints are less of a concern
Technical Note: The Search begins at the topmost layer with the fewest nodes and traverses downward through increasingly dense layers
FLAT
Architecture: Simple exhaustive search with no approximation
Performance: 100% recall but extremely slow query times (
O(n)for data sizen)Resource Usage: Index size equals the raw vector data size
Best For: Small datasets or applications requiring perfect recall
Technical Note: Performs complete distance calculations between the query vector and every vector in the database
IVF_FLAT
Architecture: Divides vector space into clusters for more efficient searching
Performance: Medium-high recall with moderate query speed (slower than HNSW but faster than FLAT)
Resource Usage: Requires less memory than FLAT but more than HNSW
Best For: Balanced applications where some recall can be traded for better performance
Technical Note: During search, only
nlistclusters are examined, significantly reducing computation
IVF_SQ8
Architecture: Applies scalar quantization to IVF_FLAT, compressing vector data
Performance: Medium recall with medium-high query speed
Resource Usage: Reduces disk, compute, and memory consumption by 70-75% compared to IVF_FLAT
Best For: Resource-constrained environments where accuracy can be slightly compromised
Technical Note: Compresses 32-bit floating-point values to 8-bit integer values
Advanced Index Options: ScaNN, DiskANN, CAGRA, and more
For developers with specialized requirements, Milvus also offers:
ScaNN: 20% faster on CPU than HNSW with similar recall rates
DiskANN: A hybrid disk/memory index that’s ideal when you need to support a large number of vectors with high recall and can accept slightly longer latency (~100ms). It balances memory usage with performance by keeping only part of the index in memory while the rest remains on disk.
GPU-based indexes:
GPU_CAGRA: This is the fastest of the GPU indexes, but it requires an inference card with GDDR memory rather than one with HBM memory
GPU_BRUTE_FORCE: Exhaustive search implemented on GPU
GPU_IVF_FLAT: GPU-accelerated version of IVF_FLAT
GPU_IVF_PQ: GPU-accelerated version of IVF with Product Quantization
HNSW-PQ/SQ/PRQ:
HNSW_SQ: Very high-speed query, limited memory resources; accepts minor compromise in recall rate.
HNSW_PQ: Medium speed query; Very limited memory resources; Accepts minor compromise in recall rate
HNSW_PRQ: Medium speed query; Very limited memory resources; Accepts minor compromise in recall rate
AUTOINDEX: Defaults to HNSW in open-source Milvus (or uses higher-performing proprietary indexes in Zilliz Cloud, the managed Milvus).
Binary, Sparse, and other specialized indexes: For specific data types and use cases. See this index doc page for more details.
Segment Size and Deployment Configuration
Segments are the fundamental building blocks of Milvus’s internal data organization. They function as data chunks that enable distributed search and load balancing across your deployment. This Milvus sizing tool offers three segment size options (512 MB, 1024 MB, 2048 MB), with 1024 MB as the default.
Understanding segments is crucial for performance optimization. As a general guideline:
512 MB segments: Best for query nodes with 4-8 GB memory
1 GB segments: Optimal for query nodes with 8-16 GB memory
2 GB segments: Recommended for query nodes with >16 GB memory
Developer Insight: Fewer, larger segments typically deliver faster search performance. For large-scale deployments, 2 GB segments often provide the best balance between memory efficiency and query speed.
Message Queue System Selection
When choosing between Pulsar and Kafka as your messaging system:
Pulsar: Recommended for new projects due to lower overhead per topic and better scalability
Kafka: May be preferable if you already have Kafka expertise or infrastructure in your organization
Enterprise Optimizations in Zilliz Cloud
For production deployments with strict performance requirements, Zilliz Cloud (the fully managed and enterprise version of Milvus on the cloud) offers additional optimizations in indexing and quantization:
Out of Memory (OOM) Prevention: Sophisticated memory management to prevent out-of-memory crashes
Compaction Optimization: Improves search performance and resource utilization
Tiered Storage: Efficiently manage hot and cold data with appropriate compute units
Standard compute units (CUs) for frequently accessed data
Tiered storage CUs for cost-effective storage of rarely accessed data
For detailed enterprise sizing options, visit the Zilliz Cloud service plans documentation.
Advanced Configuration Tips for Developers
Multiple Index Types: The sizing tool focuses on a single index. For complex applications requiring different index algorithms for various collections, create separate collections with custom configurations.
Memory Allocation: When planning your deployment, account for both vector data and index memory requirements. HNSW typically requires 2-3x the memory of the raw vector data.
Performance Testing: Before finalizing your configuration, benchmark your specific query patterns on a representative dataset.
Scale Considerations: Factor in future growth. It’s easier to start with slightly more resources than to reconfigure later.
Conclusion
The Milvus Sizing Tool provides an excellent starting point for resource planning, but remember that every application has unique requirements. For optimal performance, you’ll want to fine-tune your configuration based on your specific workload characteristics, query patterns, and scaling needs.
We’re continuously improving our tools and documentation based on user feedback. If you have questions or need further assistance with sizing your Milvus deployment, reach out to our community on GitHub or Discord.
References
- Introduction
- How to Use the Milvus Sizing Tool
- Index Selection: Balancing Storage, Cost, Accuracy, and Speed
- Segment Size and Deployment Configuration
- Message Queue System Selection
- Enterprise Optimizations in Zilliz Cloud
- Advanced Configuration Tips for Developers
- Conclusion
- References
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word