Force Merge CompactionCompatible with Milvus 3.0.x
Force Merge is designed to consolidate small and fragmented segments into fewer and larger ones to improve query performance and storage efficiency. This guide explains how to use force merge compaction.
This feature is in public preview. Do not use it in production environments.
Overview
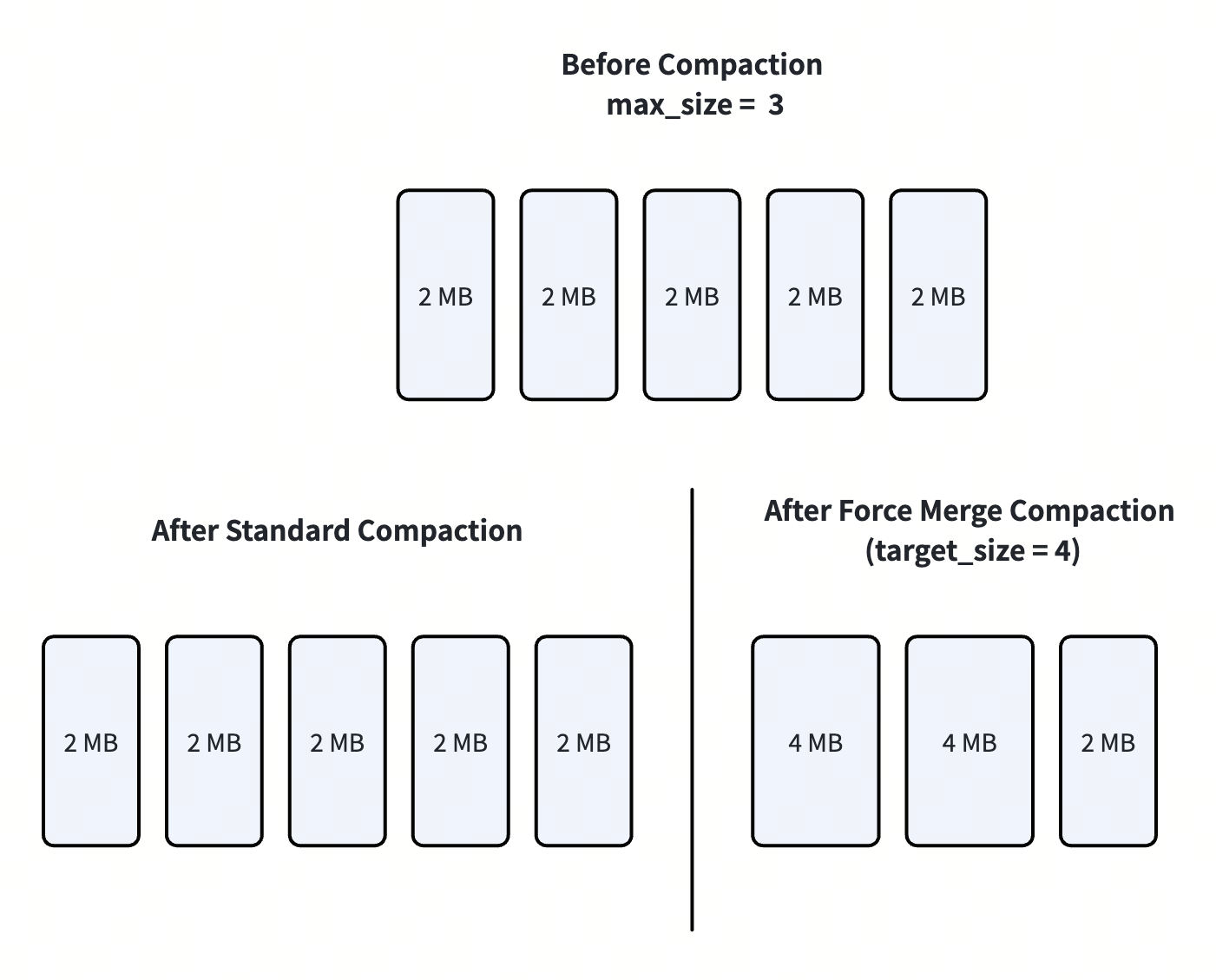
Standard compaction keeps segment sizes near the configured maxSize through many-to-one merges, but it can still leave mid-sized fragments that cannot be merged further without exceeding limits. For example, as illustrated below, if a collection has five 2 MB segments and maxSize is 3 MB, merging any two segments would exceed the limit, so standard compaction cannot further reduce the segment count and the fragmented layout remains.
Force merge adds a target_size parameter and supports reorganizing segments toward the desired size within a tight tolerance when possible. As illustrated below, if the specified target_size is 4 MB, the five 2 MB small segments can be further merged into fewer larger segments. This reduces excess segment counts, supports targets larger than the default maxSize settings, and, when the target is very large, lets the system choose a practical output size and segment count for the current hardware and QueryNode topology.
To understand which compaction method to use, see FAQ.
 R8eow3kaqhktokblcmocnvxmnee
R8eow3kaqhktokblcmocnvxmnee
Force merge compaction extends the existing Compaction API with a target_size parameter. It is fully backward-compatible: existing compaction calls without target_size continue to work as before.
Force merge operates asynchronously. It does not block search or query operations, though it consumes I/O and memory resources during execution.
Use Force Merge Compaction
Prerequisites
Milvus version 2.6.15 or later
pymilvus 2.6.13 or later
Global Configuration
The following configuration parameters control Force Merge behavior. Set them in the Milvus configuration file or via environment variables.
dataCoord:
segment:
maxSize: 512 # Default segment max size (MB).
# Used when target_size is 0 or omitted.
compaction:
maxFullSegmentThreshold: 100
# When segment count exceeds this threshold,
# a faster greedy algorithm is used instead
# of the standard merge algorithm.
forceMerge:
datanodeMemoryFactor: 4.0
# DataNode memory divided by this factor
# determines the the largest segment
# size the system can allow.
querynodeMemoryFactor: 4.0
# Minimum QueryNode memory divided by this
# factor. Used in automatic size calculation
# to ensure merged segments can be loaded.
Parameter |
Default Value |
Description |
|---|---|---|
|
512 |
Default segment max size in MB. Used as the target when |
|
100 |
Segment count threshold for algorithm selection. When the number of segments exceeds this value, Milvus uses a faster greedy algorithm for merge planning.
|
|
4.0 |
DataNode memory is divided by this factor to calculate the largest segment size the system can allow.
|
|
4.0 |
The minimum QueryNode memory is divided by this factor. Used during automatic size calculation (
|
To apply the above changes to your Milvus cluster, please follow the steps in Configure Milvus with Helm and Configure Milvus with Milvus Operators.
Trigger Force Merge Compaction
You trigger Force Merge compaction by calling compact() with the target_size parameter. For parameter details, see Parameter reference below.
Three force merge compaction modes are available:
compact("my_collection", target_size=?)
│
├─ Mode 1: target_size = 0 (or omitted)
│ Uses config maxSize (default 512 MB)
│ Equivalent to standard compaction
│
├─ Mode 2: target_size = 2048
│ Merges segments to ~2 GB each
│ Must be >= config maxSize
│
└─ Mode 3: target_size = max_int64
Auto-calculates optimal size based on
segment distribution and node memory
The following are examples to show how to use each force merge compaction mode.
Default (standard compaction)
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
# Standard compaction — uses config maxSize (default 512 MB)
job_id = client.compact("target_collection")
Explicit target size
# Merge segments to approximately 2 GB each
job_id = client.compact(
"target_collection",
target_size="2048" # The unit is MB
)
Automatic size calculation
# Let Milvus determine the optimal segment size
max_int64 = (1 << 63) - 1
job_id = client.compact(
"target_collection",
target_size=max_int64
)
Parameter reference
The following table explains the parameters.
Parameter |
Type |
Description |
|---|---|---|
|
str |
Required. The name of the collection to compact. |
|
int |
Optional. The target segment size in MB. There are 3 options of the parameter value:
|
If the specified target_size is less than the configured dataCoord.segment.maxSize, the request is rejected with an error.
Check Compaction Progress
Force Merge compaction runs asynchronously. Use the returned job ID to check progress:
# Check compaction state
state = client.get_compaction_state(job_id)
print(f"State: {state}")
Best practices
Do not use force merge compaction in production environments.
Use automatic size calculation mode for most cases. Setting
target_sizetomax_int64lets Milvus analyze your segment distribution and node resources to determine the best size. This is the recommended approach unless you have specific sizing requirements.Consider the performance trade-off. Force Merge compaction is a resource-intensive operation. It reads, merges, and rewrites segment data. Schedule it during low-traffic periods to minimize impact on query latency.
Monitor segment count before and after. Use
get_compaction_state()andlist_persistent_segmentsto verify that the compaction produced fewer, larger segments as expected.
FAQ
How is Force Merge different from standard compaction?
These two types of compaction operations serve different purposes.
Standard compaction (targetSize=0 or omitted) is a best-effort, incremental cleanup path.
Force merge (targetSize>0) is a collection-level repacking path to produce fewer, larger, near-target segments.
The key difference is merge shape: standard compaction is effectively m → 1 per task, while force merge is m → n across grouped inputs. This is why force merge can solve segment layouts that standard compaction cannot. The following table compares the 2 types of operations.
Dimension |
Standard compaction (default) |
Force merge |
|---|---|---|
API trigger |
targetSize=0 (or not set), no Major/L0 flag |
targetSize>0 (MB) |
Primary goal |
Incremental cleanup of obvious fragments; routine maintenance |
Collection-wide consolidation for search and balance |
Segment size source |
Fixed dataCoord.segment.maxSize (server config) |
User targetSize, then safety-clamped by maxSafeSize |
Parameter validity |
No user size tuning |
User targetSize must be >= dataCoord.segment.maxSize; otherwise rejected |
Safety upper bound |
Config cap only |
maxSafeSize = min(QueryNode mem, DataNode mem) / memory_factor (standalone non-pooling: further halved) |
Merge shape |
m → 1 per task, output <= configMaxSize |
m → n, outputs near targetSize |
Medium-segment behavior |
Can get stuck permanently (for example, two 60% segments cannot legally become one 120% segment) |
Repack + split works; no “stuck at 60%” pattern |
Collection flattening ability |
Limited; repeated runs may still leave many medium segments |
Strong; designed to reduce segment count and push fullness higher |
Topology awareness |
None |
Yes; uses QueryNode/replica/shard layout |
Read-path parallelism tuning |
None |
Adjusts output count using queryNodeCount / (replicas × shards) when valid |
Typical use case |
High-churn daily cleanup after writes/deletes |
Benchmark prep, search optimization, load-parallelism alignment |
Scope expectation |
Do not expect full-collection repack |
Intended for collection-level repack outcome |
Selection guidance:
Choose standard compaction for low-risk, incremental cleanup.
Choose force merge when you explicitly want to reshape the collection into fewer, larger segments aligned with search and loading behavior.
How is Force Merge different from clustering compaction?
Clustering compaction (is_clustering=True) reorganizes data within segments based on a clustering key to improve search pruning. Force Merge (target_size=N) optimizes segment sizes without changing data distribution. They serve different purposes and can be used together — run clustering compaction first to organize data, then Force Merge to consolidate the resulting segments.
Can I run Force Merge on a collection that is being queried?
Yes. Force Merge runs asynchronously and does not block queries. However, it consumes DataNode and disk I/O resources, so query latency may increase during compaction. Schedule Force Merge during low-traffic periods for best results.
What happens if I set a target_size smaller than maxSize?
The request is rejected with an error. The target size must be greater than or equal to the configured dataCoord.segment.maxSize.